Once we accept that attacks are diverse and evolving, the defense literature becomes easier to organize. It is not a random pile of papers. Most methods are trying to solve one of four problems:
- make the model survive stronger attacks during training,
- improve the training data rather than only the optimizer,
- provide formal guarantees rather than benchmark-only evidence,
- or reduce the computational cost enough for real deployment.
That four-part map is a more useful way to read the field than the raw chronology of papers.
1. Adversarial Training: Learn in a Hostile Environment
Adversarial training remains the default baseline because it directly optimizes for worst-case behavior:
$$ \min_{\theta} \mathbb{E}{(\boldsymbol{x}, y) \sim \mathcal{D}} \left[ \max{\boldsymbol{\delta} \in \mathcal{S}} \mathcal{L}(\boldsymbol{x} + \boldsymbol{\delta}, y; \theta) \right] $$
The inner loop generates hard examples; the outer loop forces the model to handle them. It works, but it is expensive and often hurts clean accuracy.
Two representative responses to those limitations are Generalized Adversarial Training (GAT) and LORE.
GAT, from Laidlaw et al., 2021, extends adversarial training beyond one perturbation family and asks how multiple semantic attacks combine.

Composite attacks are order-sensitive. GAT studies how attack composition changes the optimization problem and motivates broader adversarial training. Image source: (Laidlaw et al., 2021)
LORE, from Zhao et al., 2023, focuses on the accuracy-robustness trade-off by constraining fine-tuned embeddings to stay close to the original pre-trained representation on clean data.
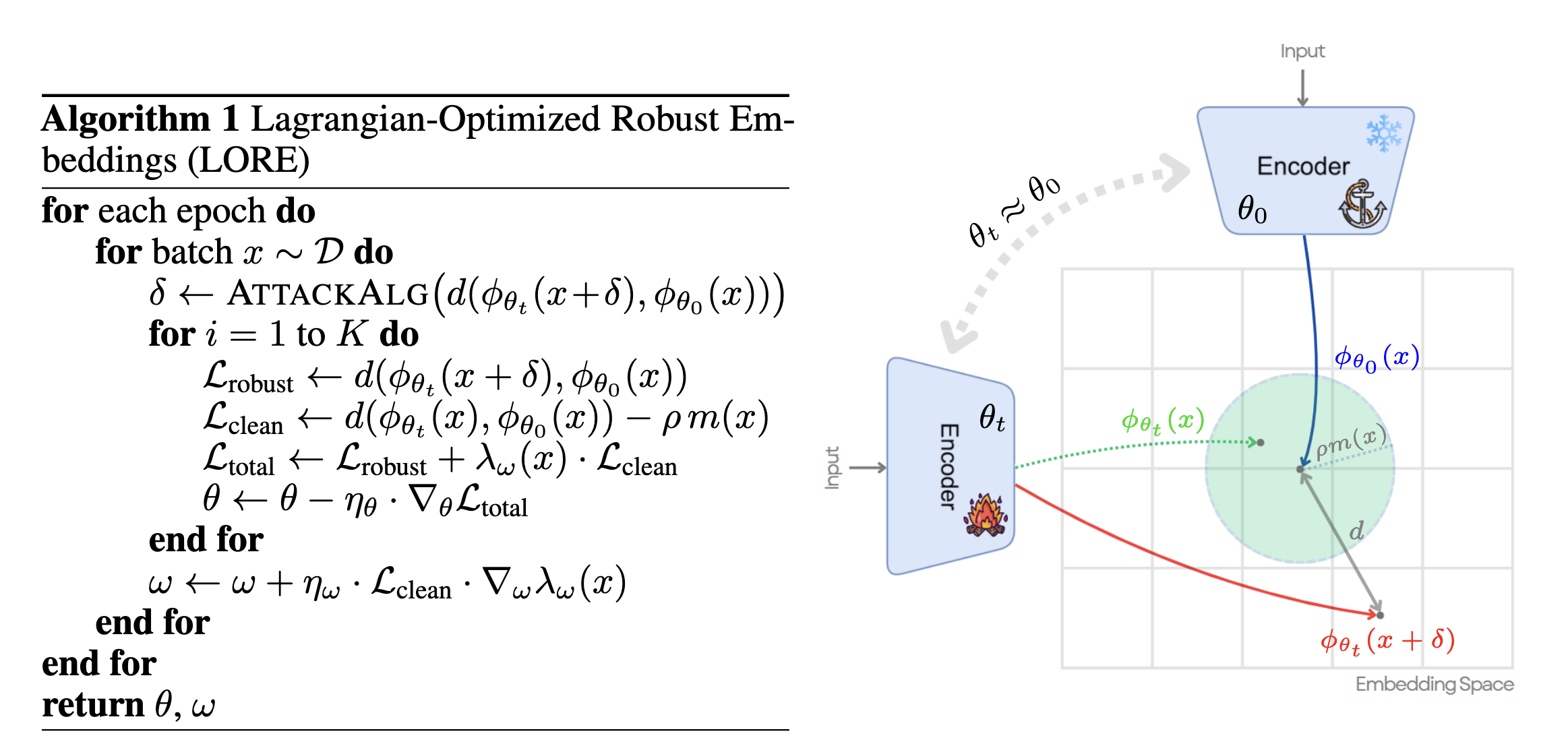
LORE treats the trade-off as constrained optimization. Rather than simply weighting clean and robust loss, it protects a clean embedding region while improving robustness. Image source: (Zhao et al., 2023)
The common idea is simple: adversarial training is still the workhorse, but it must be broadened or stabilized if we want general robustness without destroying normal performance.
2. Data-Centric Defenses: Change What the Model Learns From
Some defenses target the training distribution rather than the optimizer. The question becomes: can better data or better supervision make robust features easier to learn?
IPMix, from Lee et al., 2022, is a good example of high-diversity augmentation. It mixes image-level, patch-level, and pixel-level transformations in a structured way to enrich training coverage.
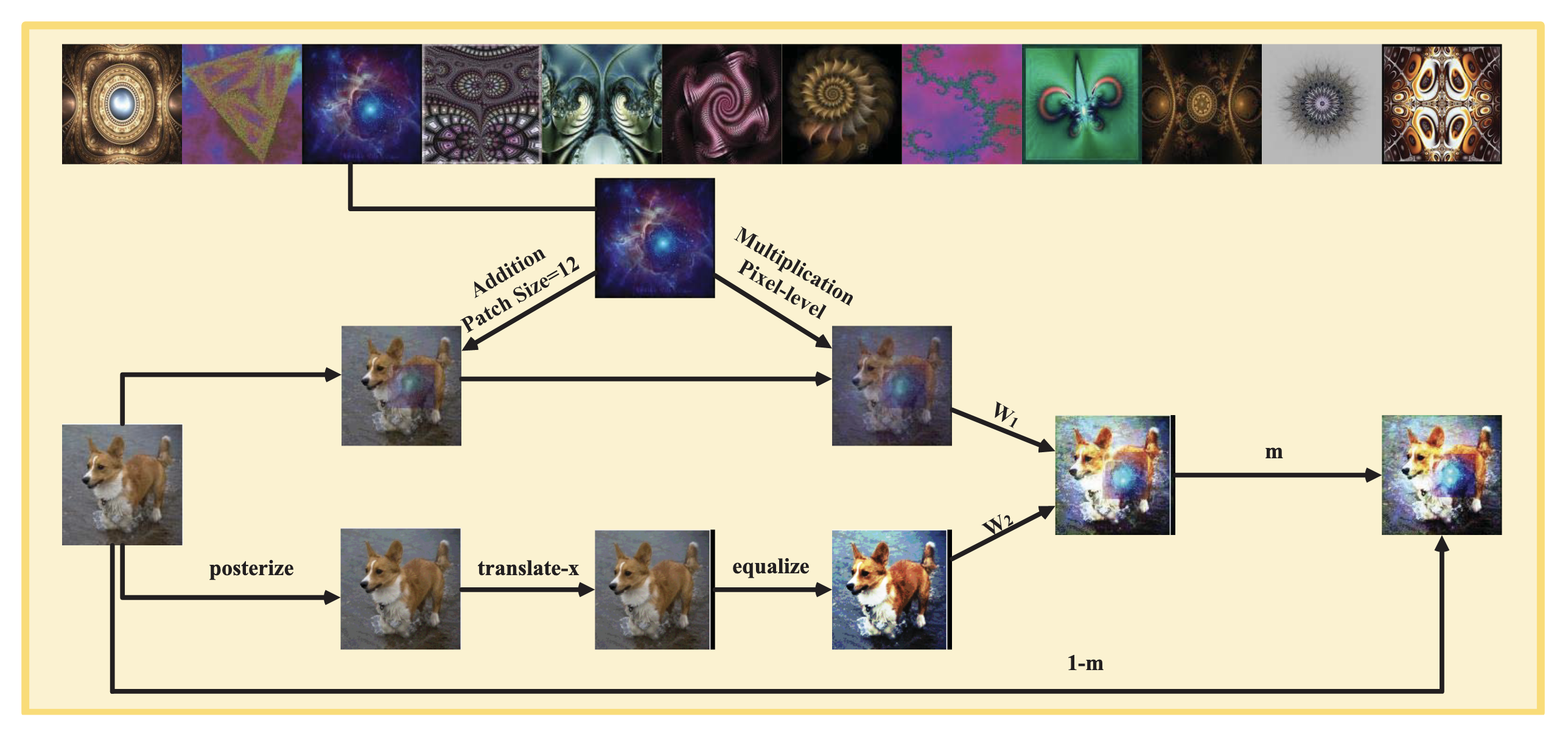
IPMix increases diversity through multi-granularity mixing. The goal is not just more data, but richer combinations of local and global structure. Image source: (Lee et al., 2022)
But more augmentation is not always better. Bai et al., 2023 show that for adversarially trained Vision Transformers, strong augmentations such as MixUp and CutMix can actually make robustness worse. Their “light recipe” works precisely because it removes that extra source of training ambiguity.
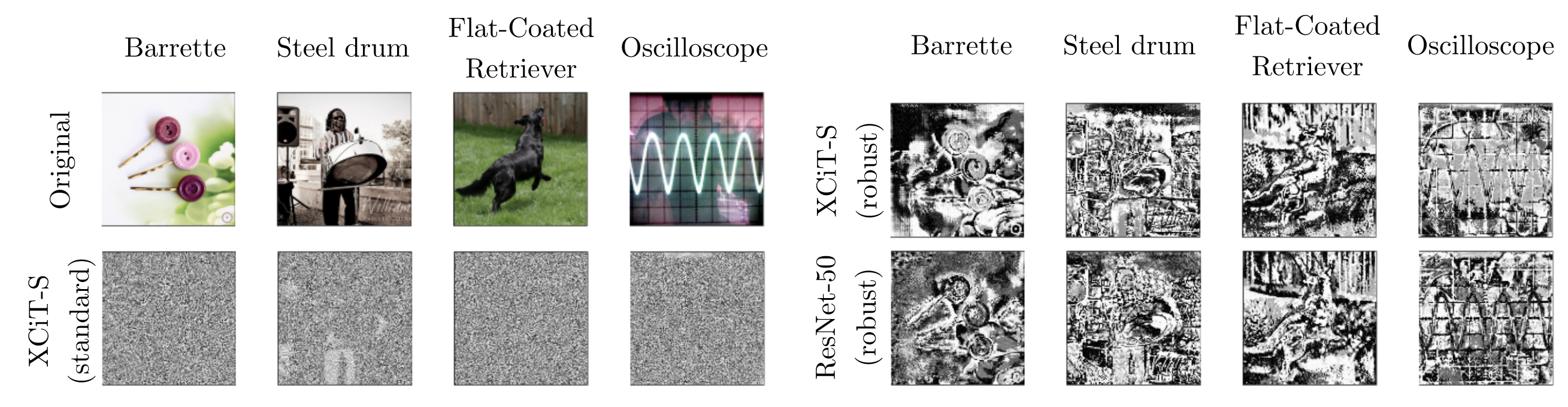
The ViT light recipe argues for less, not more. In adversarial training, strong augmentation can interfere with learning rather than help it. Image source: (Bai et al., 2023)
These two results look contradictory until we ask the right question. Data-centric defenses are not about maximizing variety in the abstract. They are about improving the quality of supervisory signal for the specific robustness objective we care about.
3. Certified and Deterministic Defenses: Stop Chasing Individual Attacks
Empirical defenses ask whether a model survives known attacks. Certified defenses ask a stronger question: can we prove the prediction stays unchanged inside a whole perturbation set?
Randomized smoothing became one of the most practical routes because it can scale beyond tiny toy networks. But it has limits, especially in high dimensions. Dual Randomized Smoothing (DRS), from Kumar et al., 2023, attacks that limitation directly by decomposing a hard high-dimensional certification problem into smaller ones.
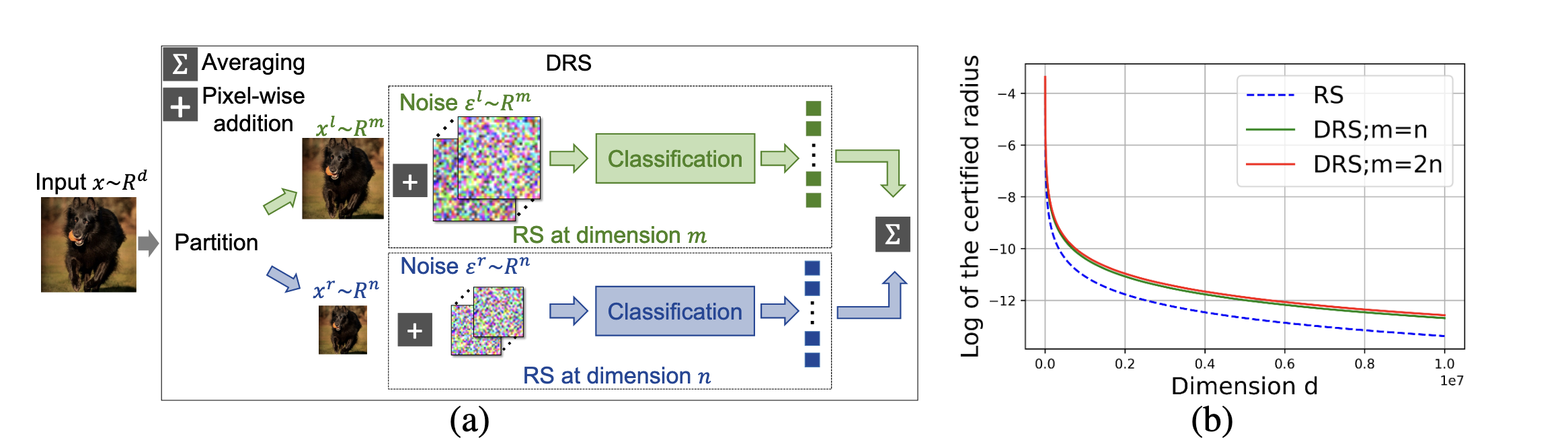
DRS as divide-and-conquer certification. Splitting the input can improve the effective certified radius in high-dimensional settings. Image source: (Kumar et al., 2023)
For applications that need deterministic guarantees rather than probabilistic ones, the literature moves further. Certified Geometric Training (CGT), from Yang et al., 2023, is representative because it brings geometric verification into training and gives verifiable boundaries for transformations such as rotation.

CGT provides explicit safety bounds. Instead of hoping a model generalizes, the method certifies that predictions remain safe within a transformation range. Image source: (Yang et al., 2023)
The key shift here is philosophical. Certification tries to replace the attack-defense arms race with a guaranteed safety boundary. That is expensive and often conservative, but in some domains it is the only standard that really matters.
4. Efficient Defenses: Make Robustness Deployable
A defense that only works with extreme compute or slow inference is hard to use in practice. That is why efficient purification remains important.
The OSCP framework from Lei et al., 2024 is a good example. Instead of long iterative purification, it aims for one-step purification while preserving semantic structure.
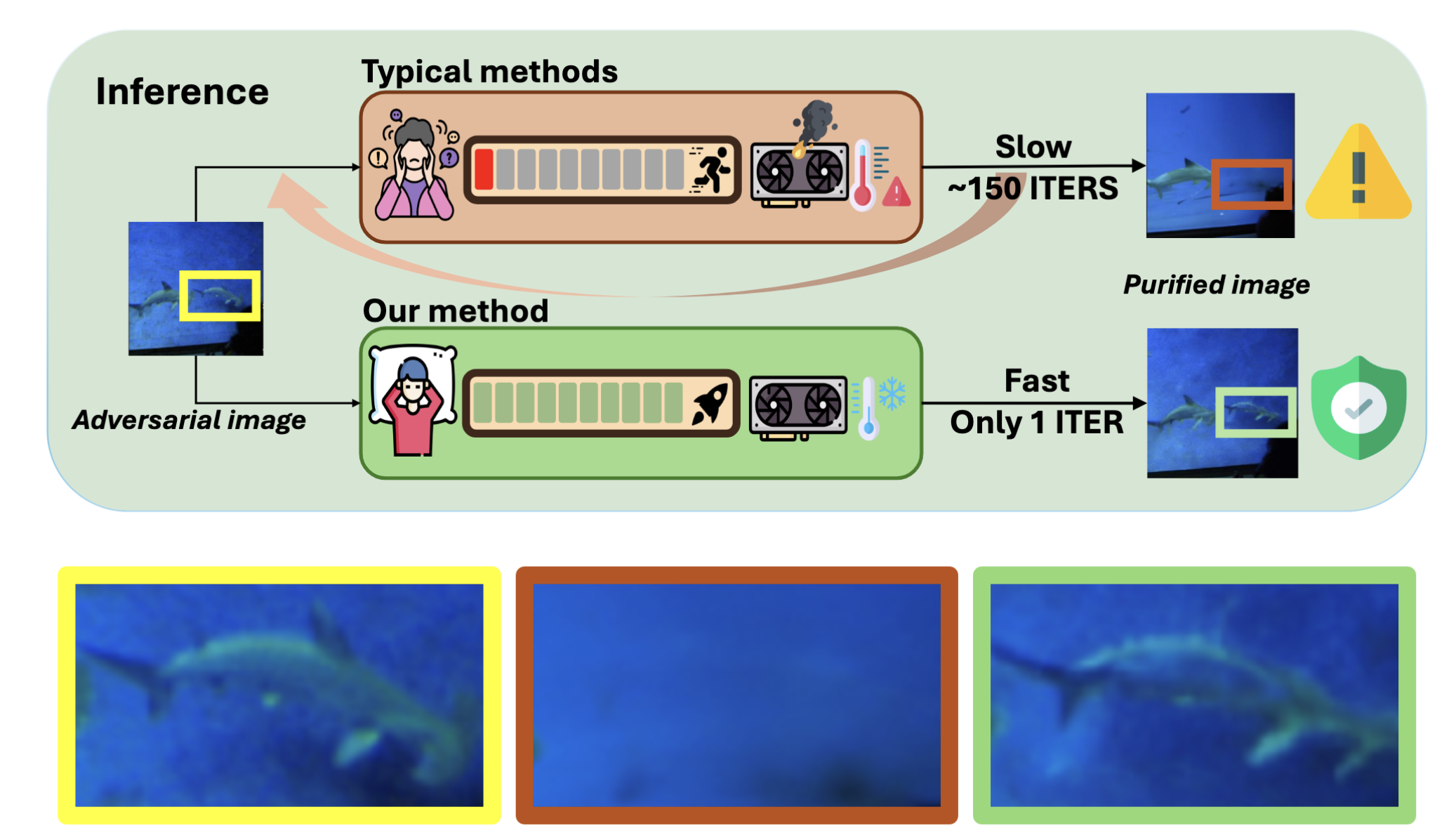
OSCP is built around the speed-versus-quality trade-off. It aims to purify quickly enough for real-time use while keeping the defense meaningful. Image source: (Lei et al., 2024)
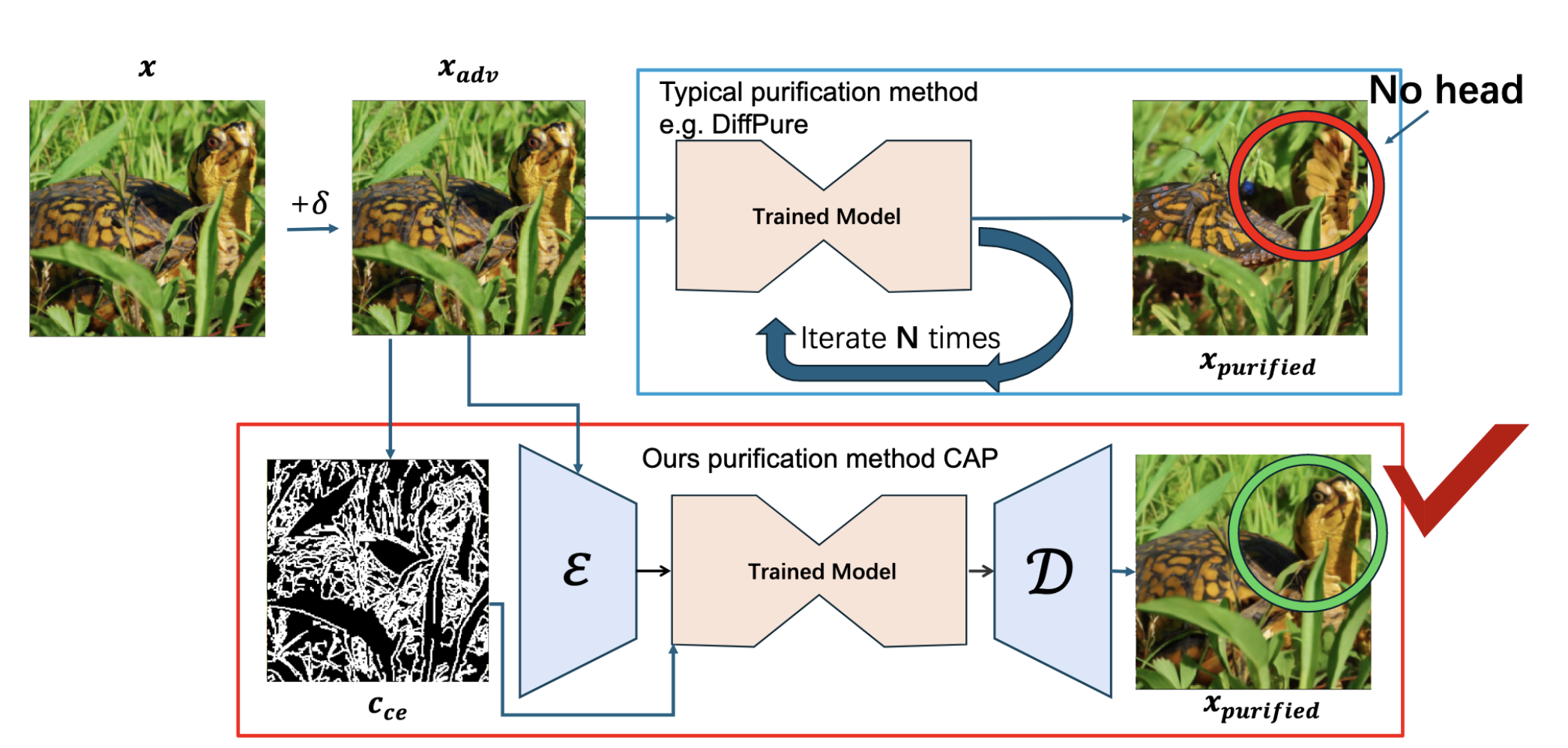
Purification quality matters. If the defense removes semantics together with noise, it can break the input even when it defeats the perturbation. Image source: (Lei et al., 2024)
Efficiency is not a side concern. It determines whether a defense can move from paper results into an actual system.
A Better Way to Read the Defense Landscape
The field becomes much easier to reason about once we treat it as four defense routes:
- adversarial training for worst-case learning,
- data-centric methods for better robust supervision,
- certification for provable guarantees,
- efficient purification for deployability.
No single route dominates every setting. The right defense depends on the threat model, the cost of errors, and the available computation. That is why robustness is best understood as a design space, not as one leaderboard.