Defenses only make sense if we are clear about the threat. That threat has changed a lot. Early adversarial machine learning focused on digital image classifiers and tiny perturbations measured in $L_p$ norms. Today, the attack surface includes 3D perception, physical transformations, multi-view consistency, and even attacks on explanations rather than predictions.
The story of adversarial robustness is therefore also a story about how the threat model expanded.
From Pixel-Space Optimization to Standard Baselines
The classic setup, summarized by Yuan et al., 2019, asks the attacker to find a perturbation $\boldsymbol{\delta}$ inside a norm-bounded set that maximizes model loss. This gives us the familiar gradient-based baselines:
- FGSM, a single-step attack along the sign of the gradient.
- PGD, a stronger iterative attack with repeated projection back into the threat set.
These attacks matter because they formalized adversarial examples as an optimization problem rather than as anecdotal failures. They also established the core intuition that gradients expose the local directions in which a model is fragile.
3D Perception Opened a Wider Surface
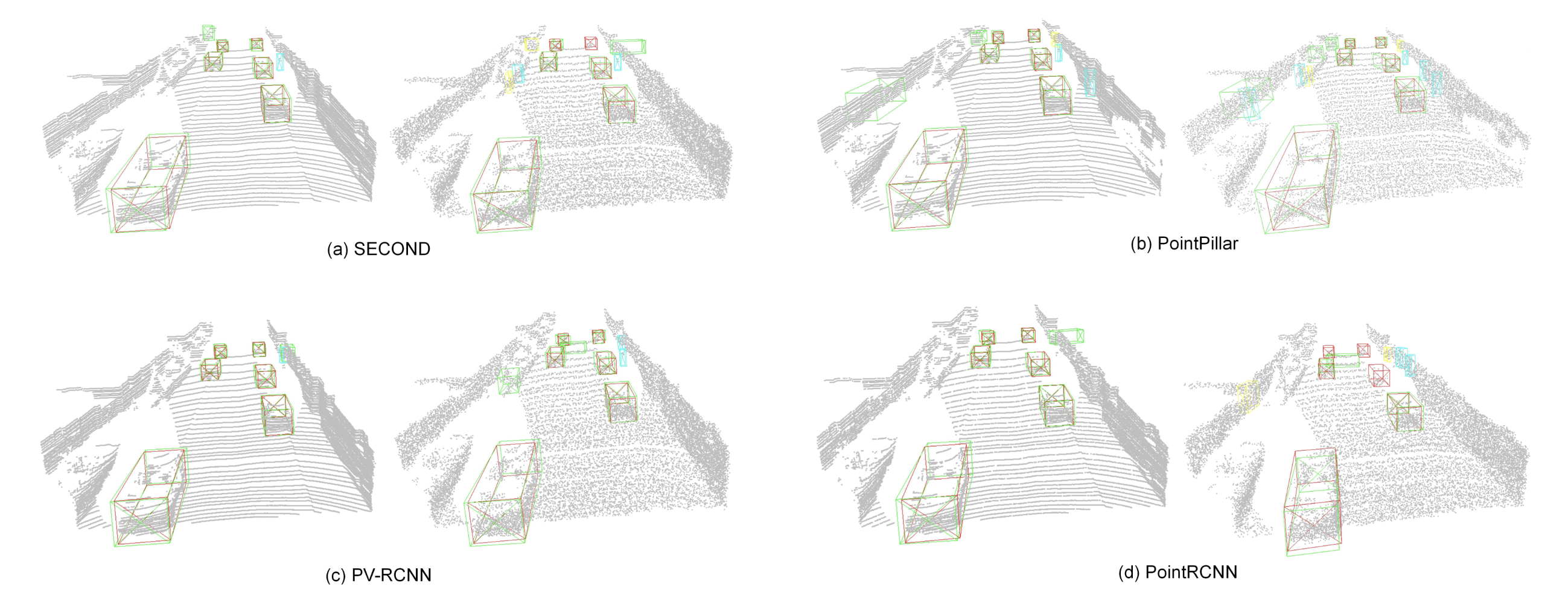
As machine learning moved into autonomous driving and robotics, the attack surface widened. The work by Zhang et al., 2023 shows how 3D detectors can fail under very small point-cloud changes.
3D detection under point perturbation. Small changes in point positions can sharply reduce detector quality. Image source: (Zhang et al., 2023)
The important shift is conceptual. In 2D, we usually think about pixel perturbations. In 3D, attackers can perturb points, remove critical points, or inject fake ones. That means vulnerability now depends on representation choices such as how the detector encodes geometry and aggregates evidence.

Point detachment via saliency. The attack first identifies which points matter most to the detector, then removes them selectively. Image source: (Zhang et al., 2023)
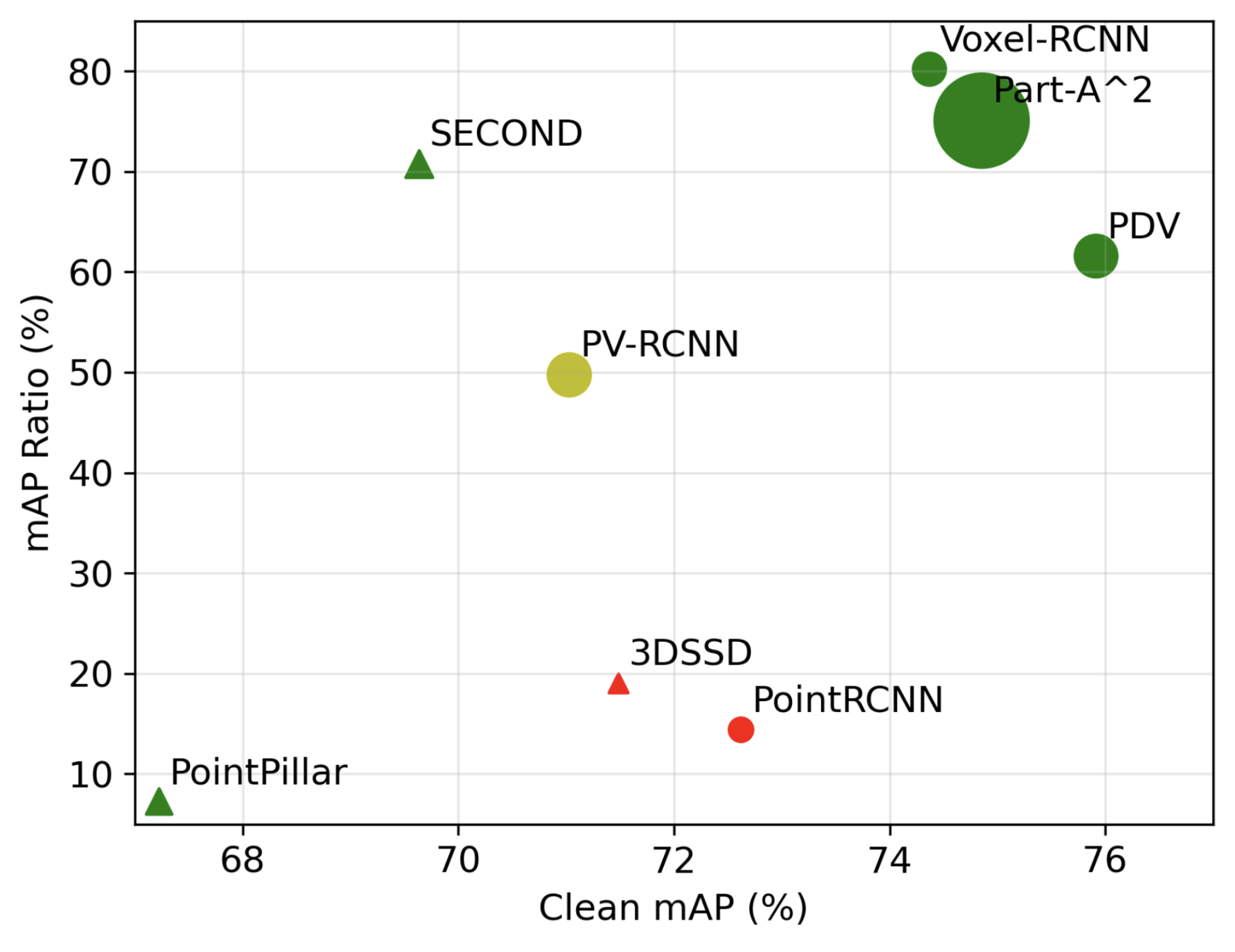
Architecture matters in 3D robustness. Voxel-based and point-based detectors do not fail in the same way or to the same degree. Image source: (Zhang et al., 2023)
This is already more realistic than pixel-space perturbation. The attack is no longer just “noise on an image.” It is targeted corruption of a perception pipeline.
The Threat Became 3D-Consistent and Semantic
Another important step is that attacks no longer need to target one rendered image at a time. Nguyen et al., 2024 attack the underlying NeRF scene representation instead of attacking a single 2D output.
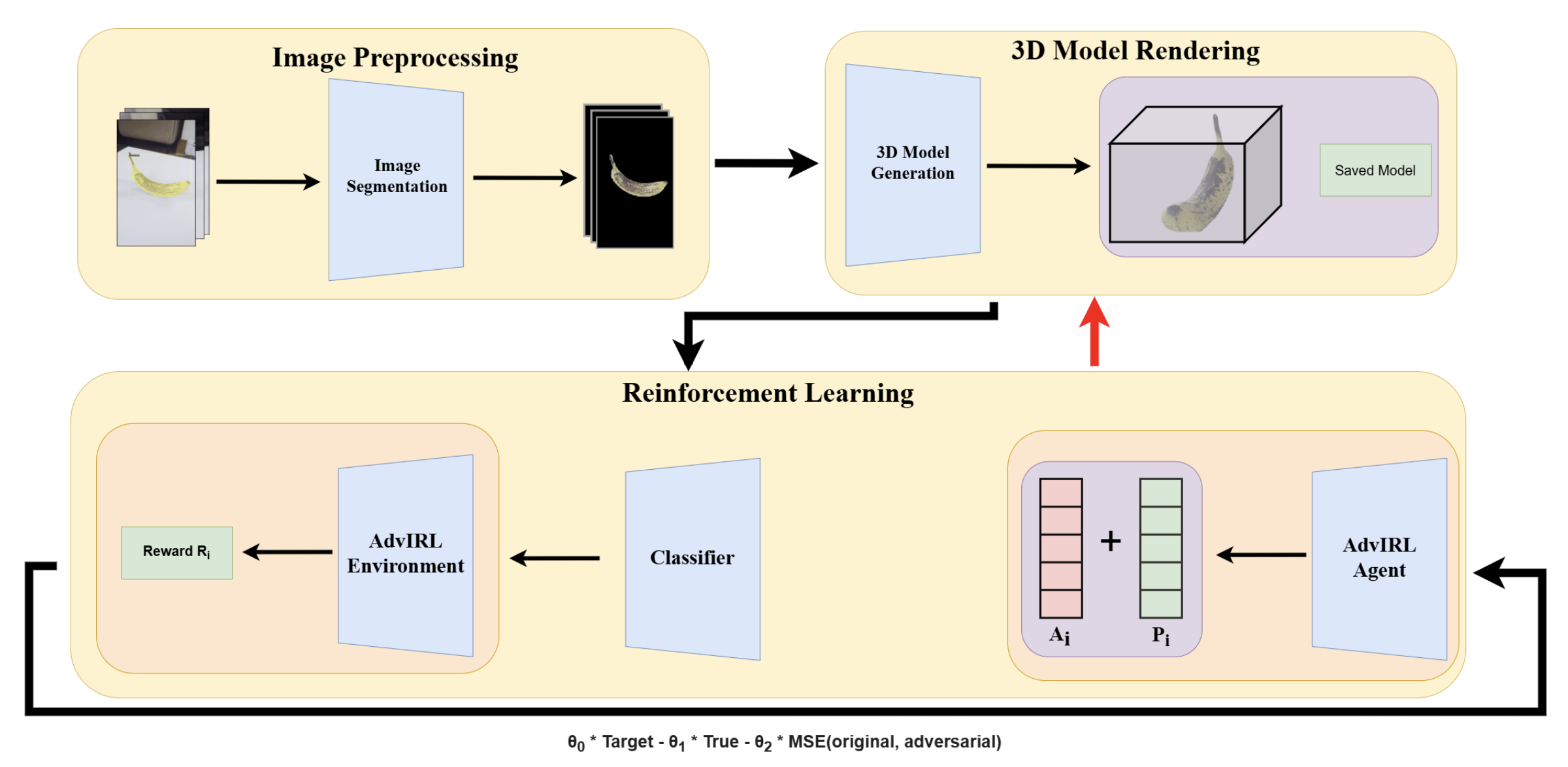
AdvIRL attacks the 3D representation itself. A reinforcement learning loop modifies NeRF parameters so that many rendered views become adversarial together. Image source: (Nguyen et al., 2024)
Once the attack moves into the 3D representation, the perturbation becomes consistent across views. This is a major change: the attack is now tied to scene structure rather than to a single frame.
At the same time, researchers began to focus on attacks that are semantically meaningful to humans. One strong example is adversarial viewpoint. Yang et al., 2024 show that a model may recognize an object confidently from one viewpoint and fail completely from another.
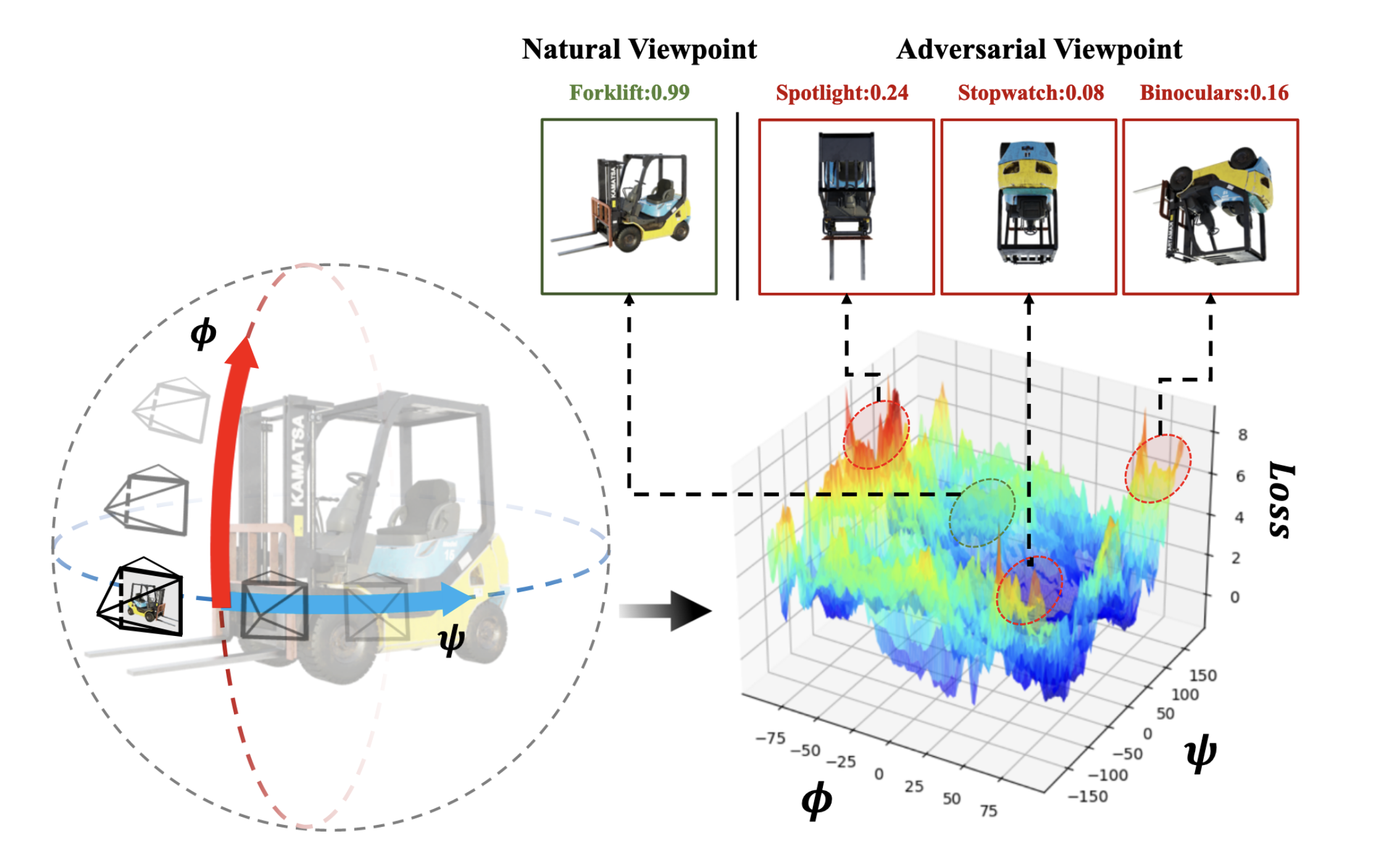
Natural versus adversarial viewpoints. A small change in viewpoint can move the model from a low-loss region into a failure region. Image source: (Yang et al., 2024)
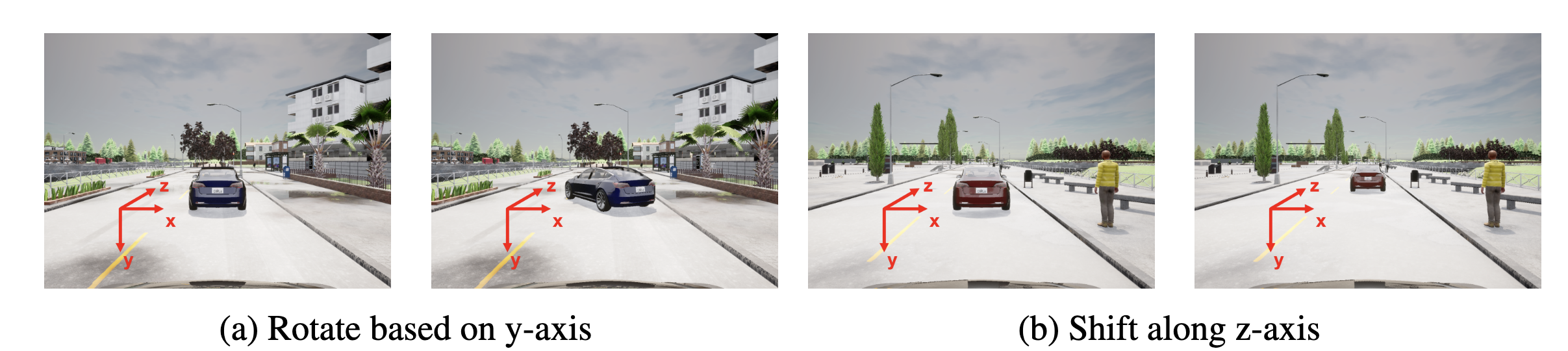
Semantic attacks in driving. Rotations and translations are not arbitrary noise; they are meaningful scene changes that can still destabilize perception. Image source: (Mao et al., 2023)
This moves adversarial robustness closer to the real world. The threat is no longer defined only by mathematical convenience. It is defined by changes that correspond to geometry, viewpoint, motion, and the physical arrangement of a scene.
The Attack Surface Now Includes Trust and Interpretation
The most unsettling extension is that attackers do not always need to change the model’s top-line prediction. They can instead target the explanation around that prediction. Baniecki & Biecek, 2024 summarize this as Adversarial Explainable AI (AdvXAI).
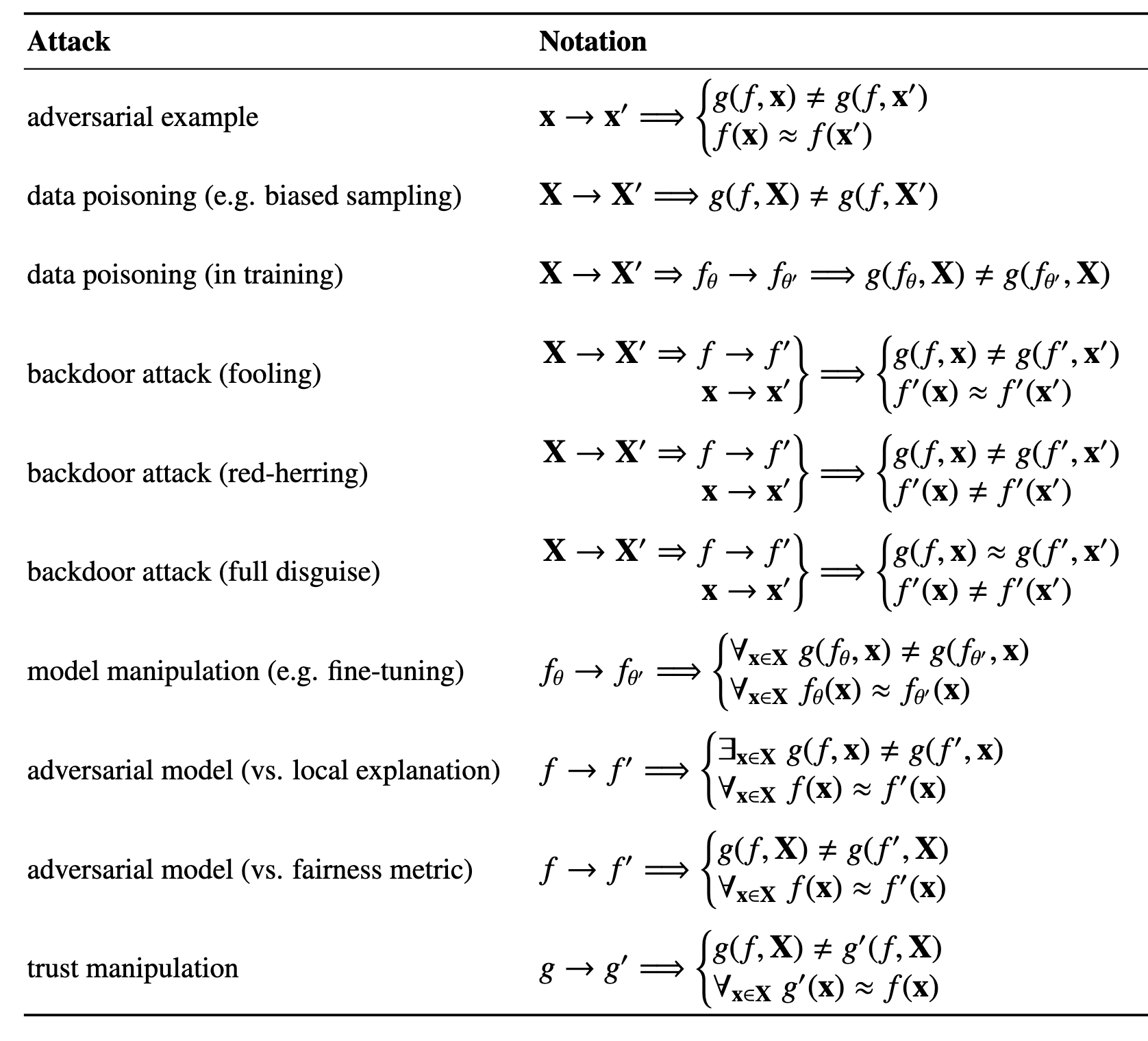
Adversarial Explainable AI expands the target. Explanations, saliency maps, and trust signals can also be attacked. Image source: (Baniecki & Biecek, 2024)
This matters because it changes the object of attack. A system can now be manipulated in ways that affect how humans audit, debug, or trust it, even if the prediction interface looks stable.
The Main Lesson
Adversarial attacks evolved along three axes:
- from 2D pixels to richer data modalities such as point clouds and 3D scenes,
- from synthetic perturbations to semantically meaningful and physical transformations,
- and from predictions to explanations and system-level trust.
That is why modern robustness research cannot be reduced to “defend against PGD.” PGD is still useful, but it is no longer the whole battlefield.