If robustness matters, the next question is obvious: what exactly are we trying to make robust? The naive answer is “make the model resist noise.” That is too shallow. Robustness is tied to the geometry of the data distribution, the smoothness of the model, and the structure of the features the model uses to decide.
This matters because many familiar trade-offs in robustness are not just implementation accidents. Some of them reflect real limits in the learning problem itself.
1. Robustness Has a Theoretical Ceiling
The work of Zhang & Sun, 2024 is useful because it reframes certified robustness in terms of data ambiguity. The core object is Bayes error, the irreducible error that remains even for an optimal classifier because class distributions overlap.

Bayes error as irreducible ambiguity. Some inputs lie in an overlapping region where uncertainty is built into the data distribution itself.
In standard learning, a model tries to fit the original distribution $\mathcal{D}$. In certified robustness, however, the model must give the same answer not just on one input $\boldsymbol{x}$, but across a neighborhood around it. That changes the target distribution. The original distribution is effectively “blurred” by the perturbation neighborhood:
$$ \mathcal{D}’ = \mathcal{D} * v $$
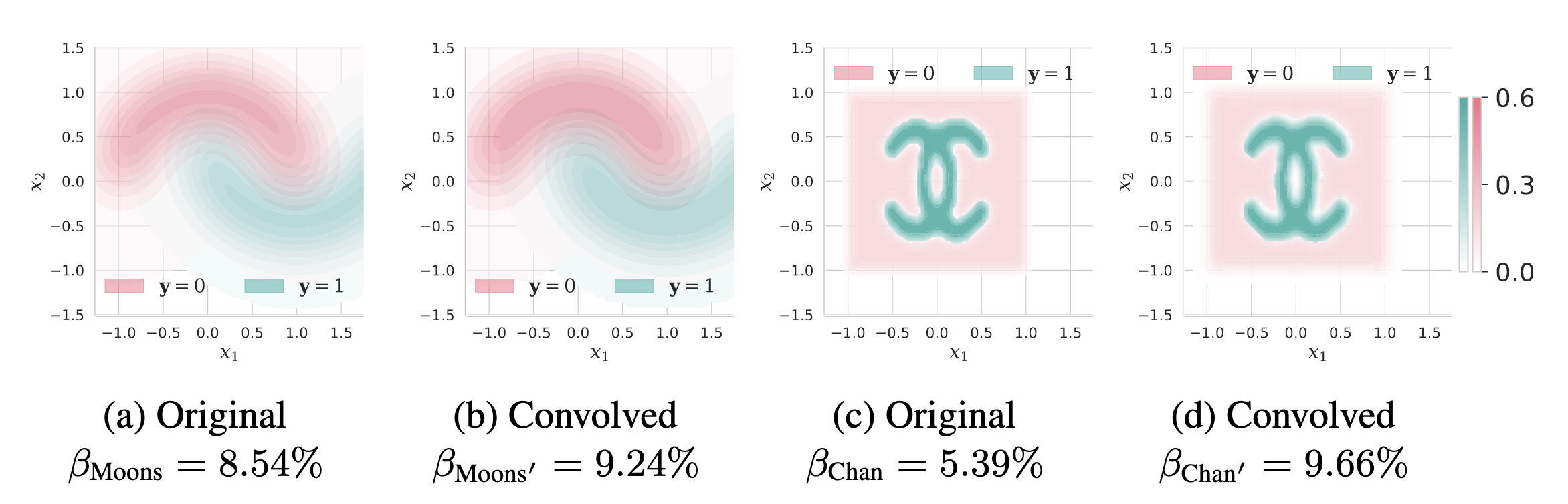
Certified robustness changes the learning problem itself. Convolution with a neighborhood distribution increases class overlap and therefore raises irreducible uncertainty.
That blurring makes class overlap worse, not better. So the robust learning problem can become intrinsically harder than the standard one. This is the cleanest explanation for why robust models often lose standard accuracy: part of the trade-off is structural, not just algorithmic.
2. Robust Models Look Different Internally
Theory is only one side of the story. We also want practical signs that a model has learned robust features rather than brittle shortcuts. Jain et al., 2023 show that one of the most informative signals is the model’s input gradient on clean samples.
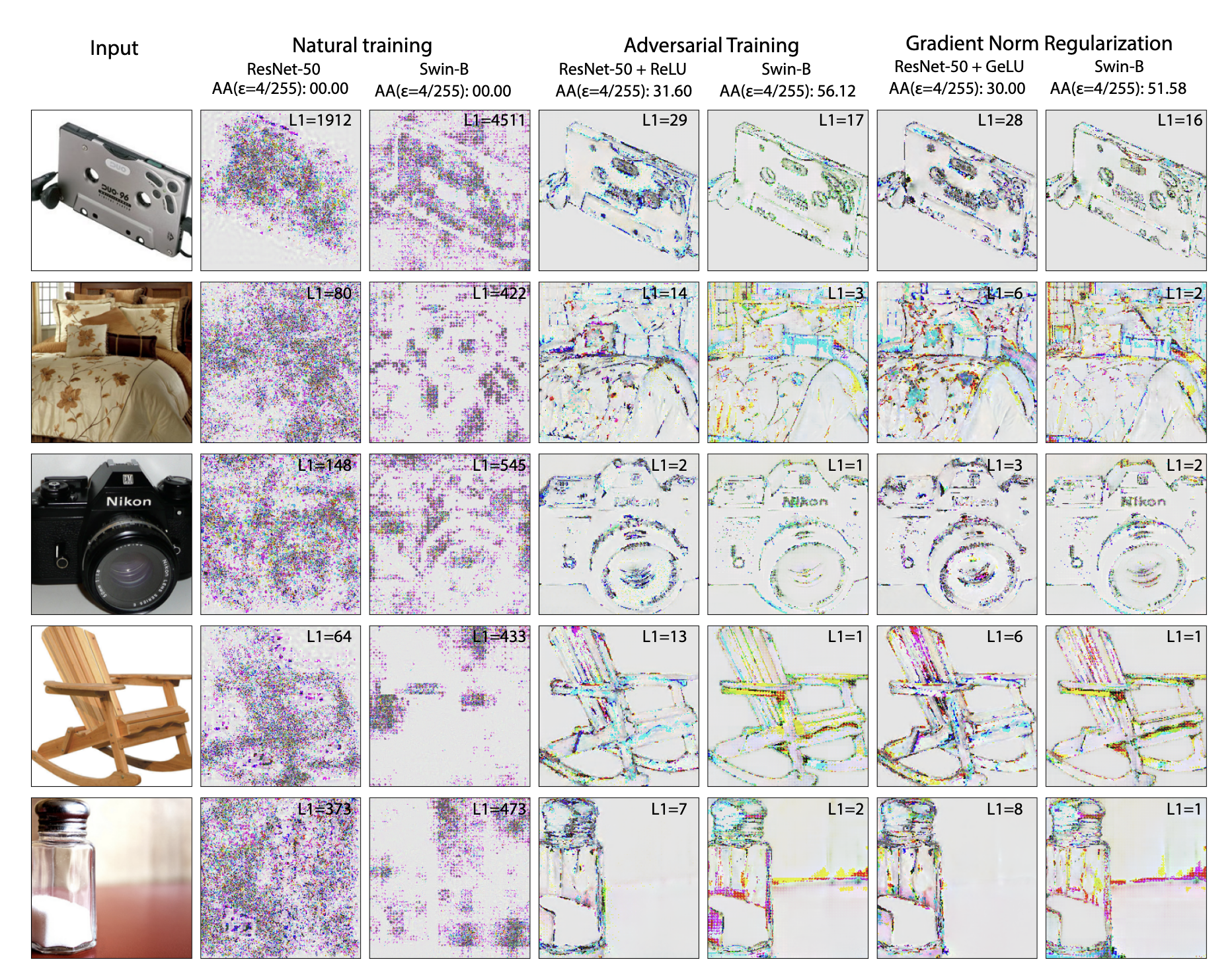
Robust and vulnerable models reveal different gradient structure. Robust gradients are more organized and human-interpretable; vulnerable ones often look noisy and unstable. Image source: (Jain et al., 2023)
The contrast is striking. Vulnerable models tend to produce chaotic, high-frequency gradients. Robust models produce gradients that look more structured and semantically aligned. Numerically, robust models also have much smaller gradient norms, suggesting smoother decision surfaces and lower sensitivity to tiny perturbations.
That difference changes what successful attacks must look like.

Effective attacks look different once a model becomes robust. Vulnerable models fall to high-frequency noise, while robust models are harder to fool without semantically meaningful perturbations. Image source: (Jain et al., 2023)
This is an important shift in perspective. Robustness is not only about “surviving stronger attacks.” It is also about whether the model relies on stable, meaningful structure rather than fragile surface correlations.
3. Loss Landscapes Explain Stability
Another useful lens is the loss landscape. A robust model should live in a region where small changes to the input or parameters do not sharply increase loss. In other words, robust models should prefer flatter, smoother basins over sharp ones.

MIMIR and smoother loss basins. Robust pre-training can guide models toward flatter, more stable regions of the optimization landscape. Image source: (Gao et al., 2023)
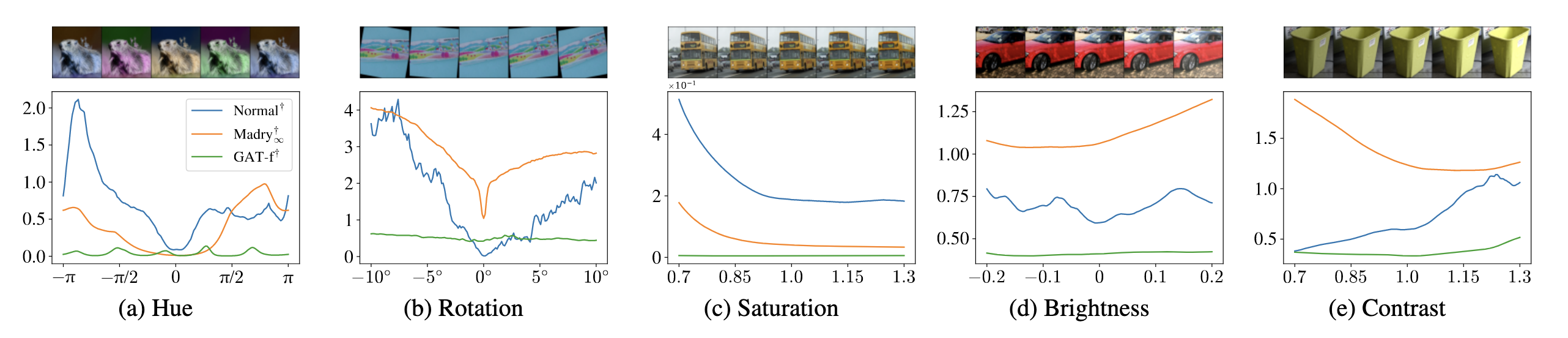
GAT under semantic attacks. Generalized adversarial training can flatten the loss landscape across multiple semantic perturbations rather than overfitting to one attack family. Image source: (Laidlaw et al., 2021)
This lens is useful because it connects optimization to behavior. A defense should not merely lower loss on a fixed benchmark attack. It should push the model toward a smoother decision space where many nearby perturbations become less dangerous by construction.
The Practical Takeaway
Robustness is not one scalar property bolted on after training. It is a combination of:
- how much irreducible uncertainty exists in the target distribution,
- whether the model’s feature usage is structured or brittle,
- and whether the decision surface is smooth enough to stay stable under perturbation.
That gives us a more rigorous question for the rest of the series. If robust models must look different internally and may face theoretical limits, what kinds of attacks are actually trying to break them?