Prefer the 5-part readable version?
This full article is still here as the reference version, but I also split it into a shorter 5-part series for easier reading and sharing.
Motivation
We are in the midst of a transformative era driven by deep learning, particularly by the large language models (LLMs) based on the Transformer architecture. These models are demonstrating capabilities that surpass human experts in a growing range of domains, operating with unprecedented efficiency and accuracy. From mastering complex intellectual challenges like Go and protein folding to accelerating drug discovery and scientific breakthroughs, the power of AI seems to be reshaping our very definition of “intelligence.”
However, in stark contrast to these powerful capabilities lies a profound and counter-intuitive vulnerability: these seemingly omnipotent tools can be remarkably fragile when faced with minute, imperceptible perturbations.

A classic example of an adversarial attack. A nearly imperceptible perturbation causes the model to misclassify a ‘panda’ as a ‘gibbon’ with extremely high confidence. Image source: (Goodfellow et al., 2015)
In the original image, a standard classification model correctly identifies the “panda” with 57.7% confidence. However, when a carefully crafted layer of “adversarial noise”—nearly invisible to the human eye—is introduced, a catastrophic failure occurs. This noise is not random; it is computed using the model’s gradient information, specifically designed to maximize the classification error. The result is not just an incorrect prediction, but one made with exceptionally high confidence (99.3%), misidentifying the panda as a “gibbon.”
This example sharply poses a fundamental question: If a model that can outperform humans on intellectual benchmarks can be so easily deceived by such a trivial “digital sleight of hand,” how can we trust it to perform high-stakes tasks like autonomous driving, medical diagnosis, or financial trading? This is precisely why enhancing model robustness is of paramount importance.
The problem, first highlighted by Goodfellow and his colleagues, has sparked an ongoing evolution of adversarial attacks and defenses. Researchers are committed to building increasingly resilient defense mechanisms (the Captain America’s shield, in our analogy) to withstand the continuous emergence of more sophisticated attack methods (Thor’s hammer).

The continuous arms race in adversarial machine learning. This is conceptualized as a battle between an unstoppable force (attacks) and an immovable object (defenses).
This post aims not merely to catalogue the latest “hammers and shields.” Our core objective is to systematically dissect and analyze these cutting-edge works to identify unexplored intersections, emerging challenges, and critical research gaps, thereby charting a course for future inquiry.
Understanding Robustness
Before delving into specific defense techniques like adversarial training or data augmentation, we must first address a few fundamental questions: What are the intrinsic theoretical limits of a defense system’s robustness? Do such boundaries exist? And how can we assess whether a model possesses inherently robust characteristics?
The ultimate limit of a deep learning model’s robustness is not dictated by our algorithms, but by the inherent ambiguity within the data distribution itself. Groundbreaking research from Zhang & Sun, 2024 leverages the concept of Bayes Error to reveal this insurmountable “theoretical ceiling.”
The core idea of Bayes error lies in the unavoidable, inherent ambiguity of data. It arises from the natural overlap between the distributions of different classes, where even a “perfect” classifier cannot make a 100% certain judgment. A widely-circulated example provides an excellent intuitive explanation for this statistical concept:

An intuitive illustration of Bayes error. The inherent ambiguity of the input data (is it a cat or a dog?) represents the irreducible error that even a perfect classifier cannot overcome.
In Figure 2(a), it is difficult to determine whether the animal is a cat or a dog based solely on its back. This input sample lies in the overlapping region of the “cat” and “dog” class distributions. More formally, for a given data distribution, the Bayes optimal classifier operates by selecting the class with the highest posterior probability for any given input. The Bayes error represents the absolute minimum error rate that even this perfect classifier cannot avoid. It quantifies the inherent, irreducible uncertainty within the data by calculating the expectation of one minus the highest class probability for each sample.
The core insight from Zhang & Sun, 2024 is that the pursuit of certified robustness fundamentally alters the data distribution the model needs to learn. Standard training aims to fit the original data distribution $\mathcal{D}$. Certified training, however, requires the model to yield the same prediction for an input $\boldsymbol{x}$ and its entire surrounding neighborhood $\mathcal{V_x}$. This is equivalent to “smearing” the label of $\boldsymbol{x}$ across the whole neighborhood. When this is done for all data points, the process is mathematically equivalent to a convolution of the original distribution $\mathcal{D}$ with a function $v$ representing the neighborhood, forming a new, “blurred” distribution $\mathcal{D}’ = \mathcal{D} * v$.
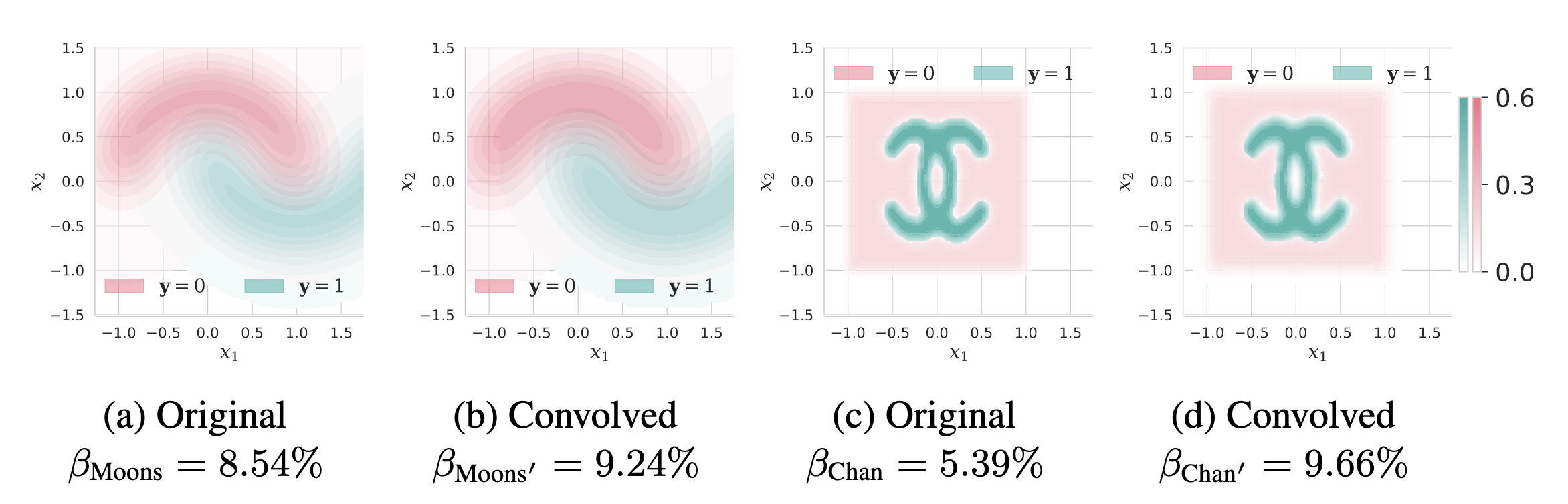
The effect of convolution on data distributions. The process of certified robustness effectively ‘blurs’ the original distribution (left), increasing the overlap between classes (right) and thereby raising the inherent Bayes error. (Concept from Zhang and Sun, 2024)
This “blurring” inevitably leads to an increase in the Bayes error. The paper rigorously proves that the convolution process will necessarily increase or maintain the system’s inherent uncertainty, formally stated as $\beta_{\mathcal{D}’} \ge \beta_{\mathcal{D}}$. This implies that for a model to become robust, the learning task itself becomes inherently more difficult. Therefore, the drop in accuracy for robust models is not solely a flaw of the algorithm but is rooted in the higher, unavoidable error rate of the target distribution it optimizes. The research further derives a computable Irreducible Robustness Error, $\zeta_D$, establishing the theoretical upper bound of certified robust accuracy at $1 - \zeta_D$. This upper bound fundamentally explains the trade-off between improving model robustness and sacrificing standard accuracy.
Given that model robustness has a theoretical ceiling, how can we evaluate whether a model possesses inherently robust features? The work by Jain et al., 2023 provides an elegant and efficient method: by observing the model’s “input gradients” on normal, clean samples, we can easily identify its level of robustness.
Input gradients can be understood as the model’s “attention map” or “sensitivity distribution,” revealing the degree to which it relies on input features for its decisions. Their research finds significant, systematic differences between the input gradients of vulnerable and robust models.
A comparison of input gradients on clean samples for vulnerable versus robust models. Robust models exhibit structured, human-interpretable gradients, whereas vulnerable models show chaotic, high-frequency noise. Image source: (Jain et al., 2023)
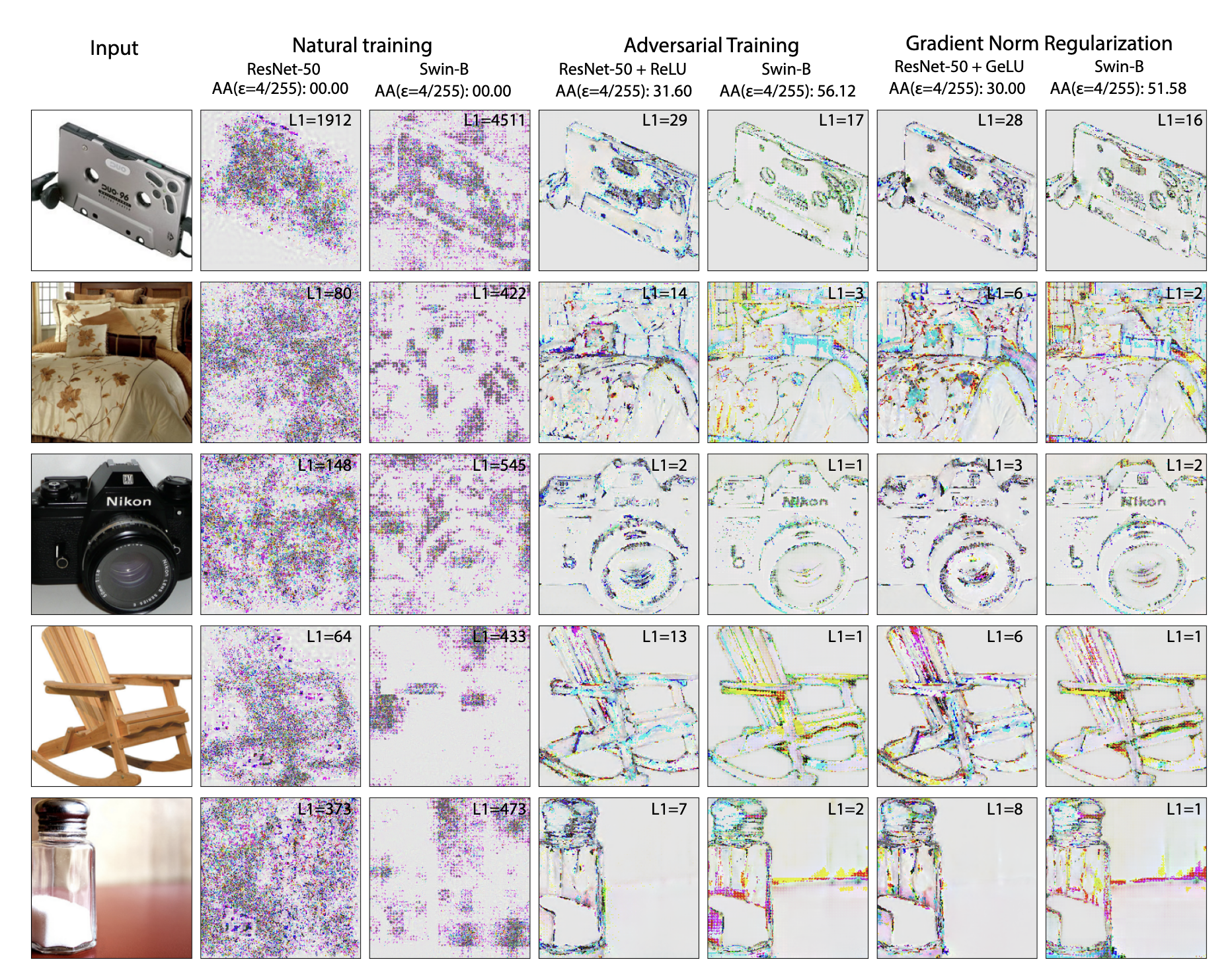
This finding is not only visually intuitive but also numerically validated. The gradient norms of robust models are about two orders of magnitude lower than those of vulnerable models, implying their decision function surfaces are much “smoother” and less sensitive to small input changes. This intrinsic difference also dictates the types of attacks that are effective against them.

Visualization of adversarial perturbations for different models. Attacks on vulnerable models consist of high-frequency noise, while attacks on robust models must contain semantic structures similar to the original image to be effective. Image source: (Jain et al., 2023)
A model’s robustness is deeply reflected in its gradient response to normal inputs and the nature of attacks that can threaten it. A robust model focuses on structure and, therefore, can only be challenged by structured attacks. This provides a new dimension for rapidly assessing model robustness without resorting to expensive attack-based testing.
A robust model should maintain a stable decision boundary in the face of input perturbations. This stability can be visualized through the “Loss Landscape,” which depicts how the loss function (the degree of error) changes with slight variations in model parameters or inputs.
An ideally robust model should possess a wide, flat loss landscape in both its parameter and input spaces, rather than a sharp, steep one. In a flat region, small perturbations do not cause drastic increases in the loss value, indicating more stable model performance.
This notion is validated from different perspectives by research from Xu et al. (2023) and in the work on Generalized Adversarial Training (GAT) by Laidlaw et al., 2021.

A smoother loss landscape resulting from MIMIR pre-training. Compared to the baseline MAE, models pre-trained with MIMIR (first and last columns) converge to broader, flatter loss basins, indicating greater stability. Image source: (Gao et al., 2023)
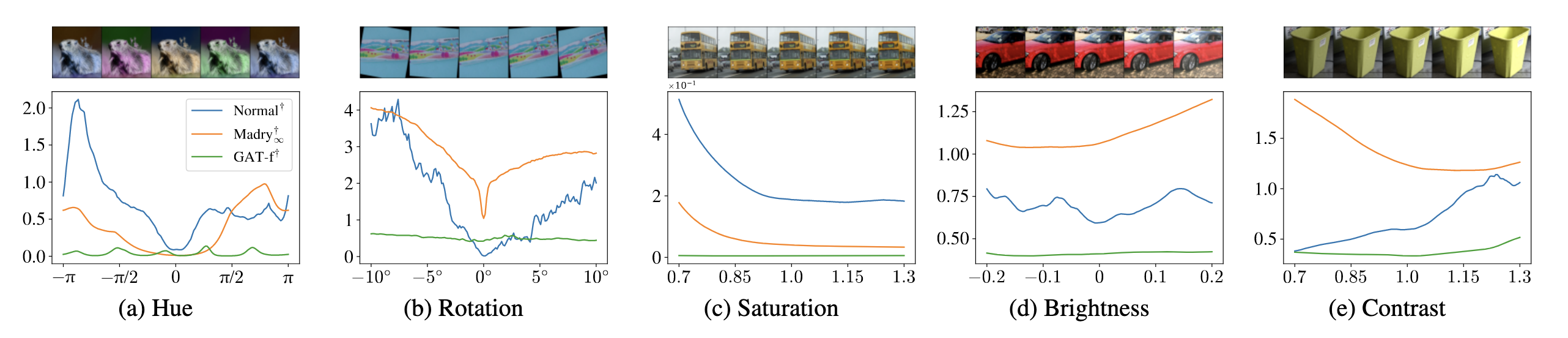
The smooth loss landscape of GAT under various semantic attacks. When faced with multiple semantic attacks such as changes in hue, rotation, and saturation, the standard model’s loss landscape (blue curve) is filled with dramatically fluctuating high peaks, indicating extreme vulnerability. In contrast, the model trained with GAT (green curve) exhibits a loss landscape that is exceptionally flat and close to the bottom. This demonstrates that GAT does not simply defend against specific attacks but fundamentally shapes a smoother, more stable decision space, making it ‘immune’ to a wide variety of input perturbations. Image source: (Laidlaw et al., 2021)
The loss landscape offers a deeper perspective for understanding robustness. An effective defense mechanism should not merely aim to reduce loss on certain adversarial examples, but should reshape the entire loss landscape, guiding the model towards an inherently smoother and more stable state.
The Evolving Threats
Effective defense must be built upon a deep understanding of the threats. In the field of deep learning security, adversarial attacks are far from static; they continuously evolve in response to advancements in defense technologies.
Early research on adversarial attacks, as summarized in surveys like the one by Yuan et al., 2019, primarily focused on the digital image space, using $L_p$ norms to measure the “imperceptibility” of perturbations. The goal of such attacks is to find a perturbation $\boldsymbol{\delta}$ within an $L_p$-norm ball $\mathcal{S}$ of radius $\epsilon$ centered at the original input $\boldsymbol{x}$ that maximizes the model’s loss. Classic methods largely rely on the model’s gradient information. For example, the Fast Gradient Sign Method (FGSM) adds a perturbation in the direction of the loss function’s gradient $\nabla_{\boldsymbol{x}} \mathcal{L}(\boldsymbol{x}, y; \theta)$ in a single step, while Projected Gradient Descent (PGD) iteratively updates the perturbation in small steps and projects it back into the $L_p$-norm ball, often finding more effective attacks. These gradient-based optimization methods form the cornerstone of adversarial attack research.
With the rise of technologies like autonomous driving, the focus of attacks has gradually shifted from 2D images to more complex 3D perception systems. Zhang et al., 2023 conducted a comprehensive robustness evaluation in this domain, extending classic attack ideas to 3D point clouds.
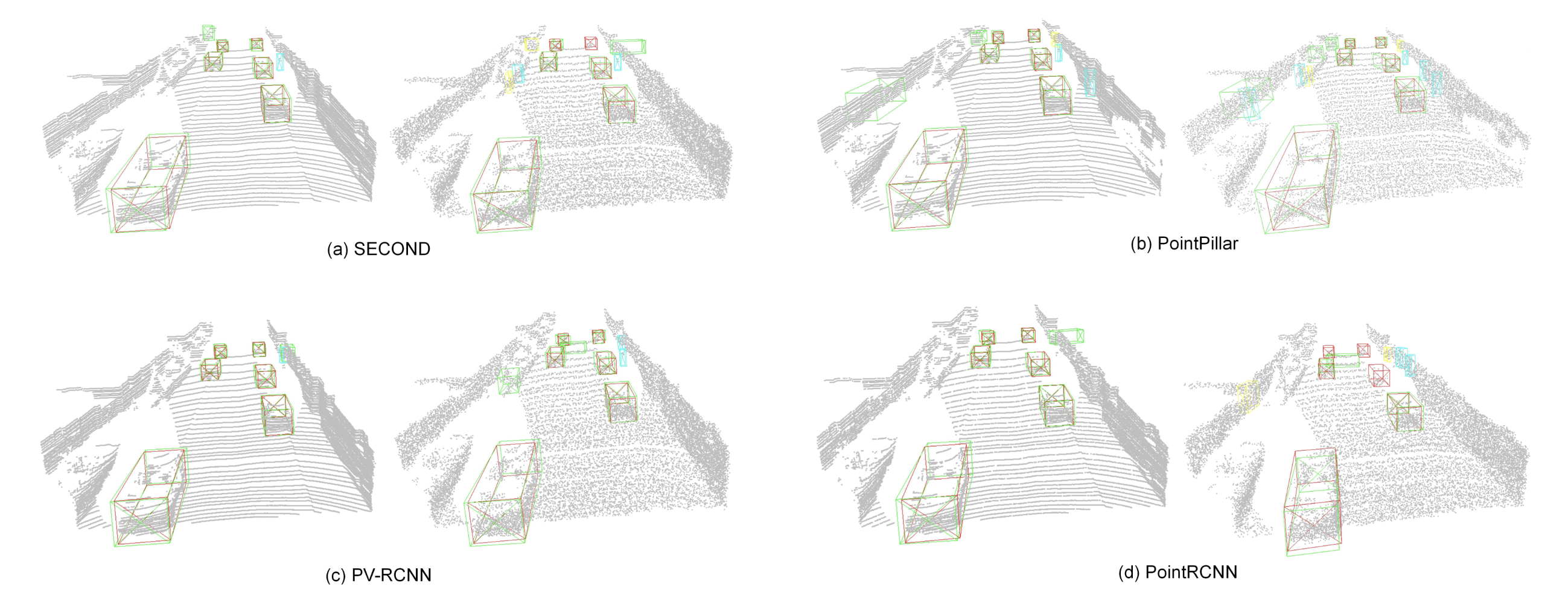
The effect of adversarial point perturbation attacks on mainstream 3D detectors. As shown, minute perturbations to a point cloud (point displacements of less than 10cm), imperceptible to the human eye, can cause a sharp decline in the performance of various mainstream 3D detection models, including SECOND, PointPillar, and PV-RCNN, leading to numerous false negatives and false positives. Image source: (Zhang et al., 2023)
The study systematically analyzes three types of attacks: Point Perturbation, which involves slightly shifting the 3D coordinates of each point; Point Detachment, which removes a small number of critical points; and Point Attachment, which adds optimized “fake” points in vulnerable areas of the scene. The effectiveness of detachment and attachment relies on locating “critical points” or “vulnerable regions,” which is typically achieved by generating a saliency map based on the gradient of the loss function with respect to each point’s coordinates.

The process of a saliency-map-based point detachment attack. An attacker first generates an ‘importance map’ via gradient computation (a), where warmer colors indicate points with a greater impact on the detection result. The attacker then precisely and iteratively removes these critical points, which are primarily distributed on the object’s surface (b, c, d), thereby compromising the model’s perception with minimal cost. Image source: (Zhang et al., 2023)
Beyond point clouds, emerging 3D representation methods like Neural Radiance Fields (NeRF) have also exposed new attack surfaces. Nguyen et al., 2024 proposed an innovative framework for attacking NeRF models in a black-box setting. The core idea is to shift from manipulating the pixels of 2D rendered images to directly modifying the parameters of the NeRF model itself through reinforcement learning. This creates an inherently adversarial 3D scene from which any rendered 2D view will possess adversarial properties.
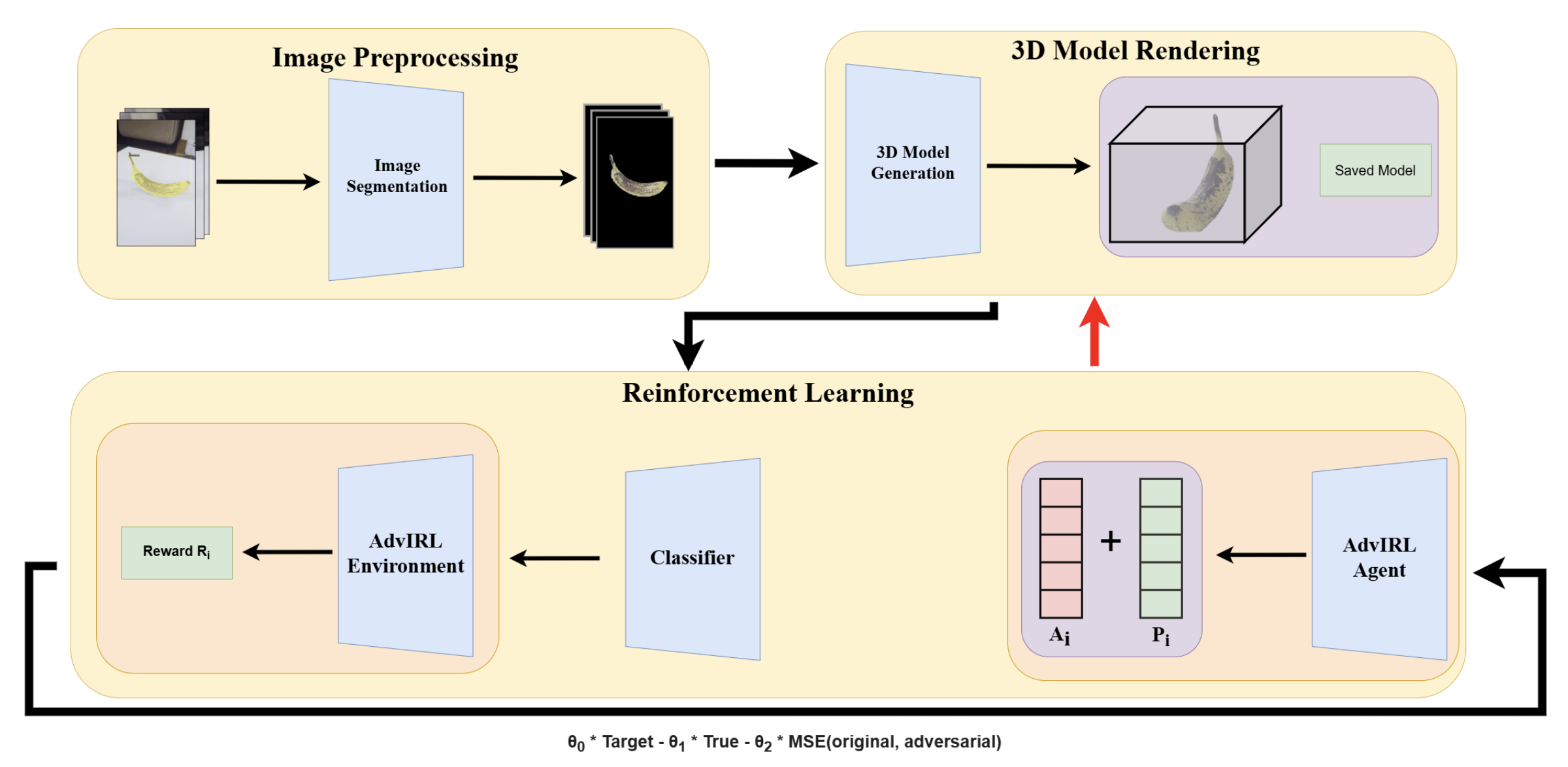
The workflow of the AdvIRL framework. A reinforcement learning agent iteratively fine-tunes the NeRF model’s parameters, optimizing based on feedback from a target classifier to train a 3D model that consistently generates adversarial views. Image source: (Nguyen et al., 2024)
The elegance of this method lies in its shift of focus from the vulnerability of individual 2D images to the vulnerability of the 3D representation itself, making the resulting adversarial noise inherently robust to 3D transformations like rotation and scaling.

Overview of adversarial examples generated by AdvIRL. The method achieves success across various scenes. The leftmost image in each row is the original, unattacked rendering, while the columns to the right show adversarial images rendered from different viewpoints after the AdvIRL attack. The adversarial noise (mainly color and texture distortions) is consistent in 3D space. Image source: (Nguyen et al., 2024)
To demonstrate its attack capabilities more concretely, let’s look at a few examples. In an attack targeting a lighthouse scene, AdvIRL successfully caused the model to misclassify.

A targeted attack on the lighthouse scene. This is an adversarial rendering generated by AdvIRL with the goal of making the classifier misidentify the ’lighthouse’ as a ‘boathouse.’ The attack successfully achieved this with a 50% classification confidence. Subfigures (a)-(d) show renderings from different angles, demonstrating the attack’s effectiveness across multiple viewpoints. Image source: (Nguyen et al., 2024)
In simulations relevant to safety-critical domains like autonomous driving, the threat is even more palpable. The researchers launched a targeted attack on a truck scene, aiming to have the model identify it as a “cannon.”

Images generated from different angles of the adversarially perturbed truck. This targeted attack was remarkably successful, with 15 out of 20 renderings from different viewpoints being misclassified as ‘cannon,’ with confidence levels ranging from 15% to 70%. This highlights the potential risk of such attacks on visual models in applications like autonomous driving. Image source: (Nguyen et al., 2024)
While $L_p$-norm attacks are mathematically tractable, they often diverge from real-world physical perturbations. Consequently, research is increasingly shifting towards more semantically meaningful attacks that directly manipulate our perceptual dimensions, such as object geometry and viewpoint.
The work by Yang et al., 2024 profoundly reveals the extreme vulnerability of modern visual models in this dimension. The study points out that a model’s performance can fluctuate dramatically with changes in viewpoint, with multiple “adversarial viewpoint” regions where even a slight change can cause the model to switch from a correct identification to a completely wrong one.
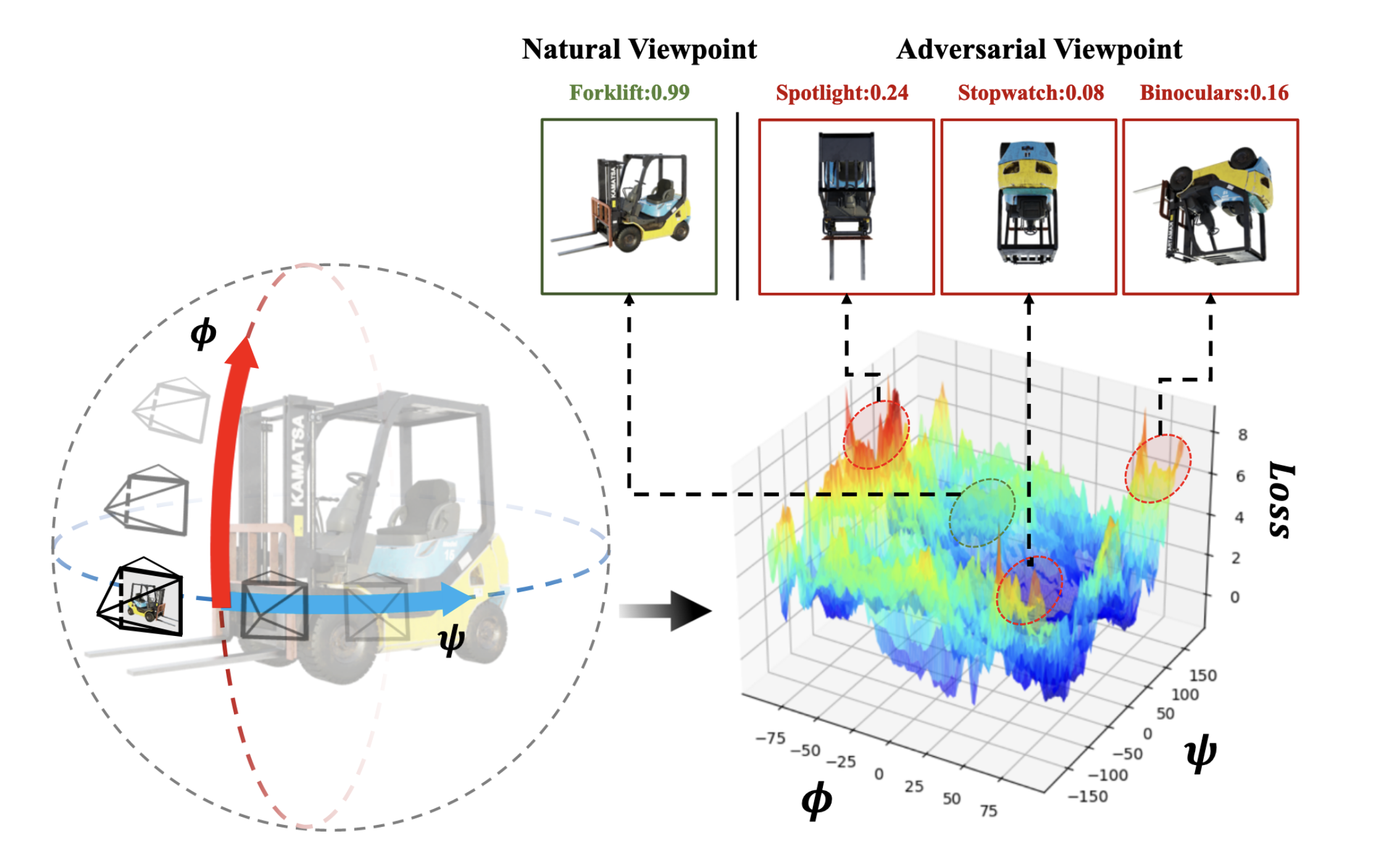
A comparison between natural and adversarial viewpoints. The same forklift model is correctly identified with high confidence (0.99) from a ‘Natural Viewpoint.’ However, when observed from certain uncommon ‘Adversarial Viewpoints,’ the same model fails completely, misidentifying it as unrelated objects like a ‘spotlight’ or ‘stopwatch.’ The loss landscape in the bottom right intuitively illustrates this: natural viewpoints correspond to low-loss ‘valleys,’ while multiple adversarial viewpoints correspond to high-loss ‘peaks.’ Image source: (Yang et al., 2024)
To systematically study and defend against such attacks, the researchers proposed the Viewpoint-Invariant Adversarial Training (VIAT) framework. At its core is a min-max optimization process designed to find and leverage the most confusing viewpoints to train the classifier.
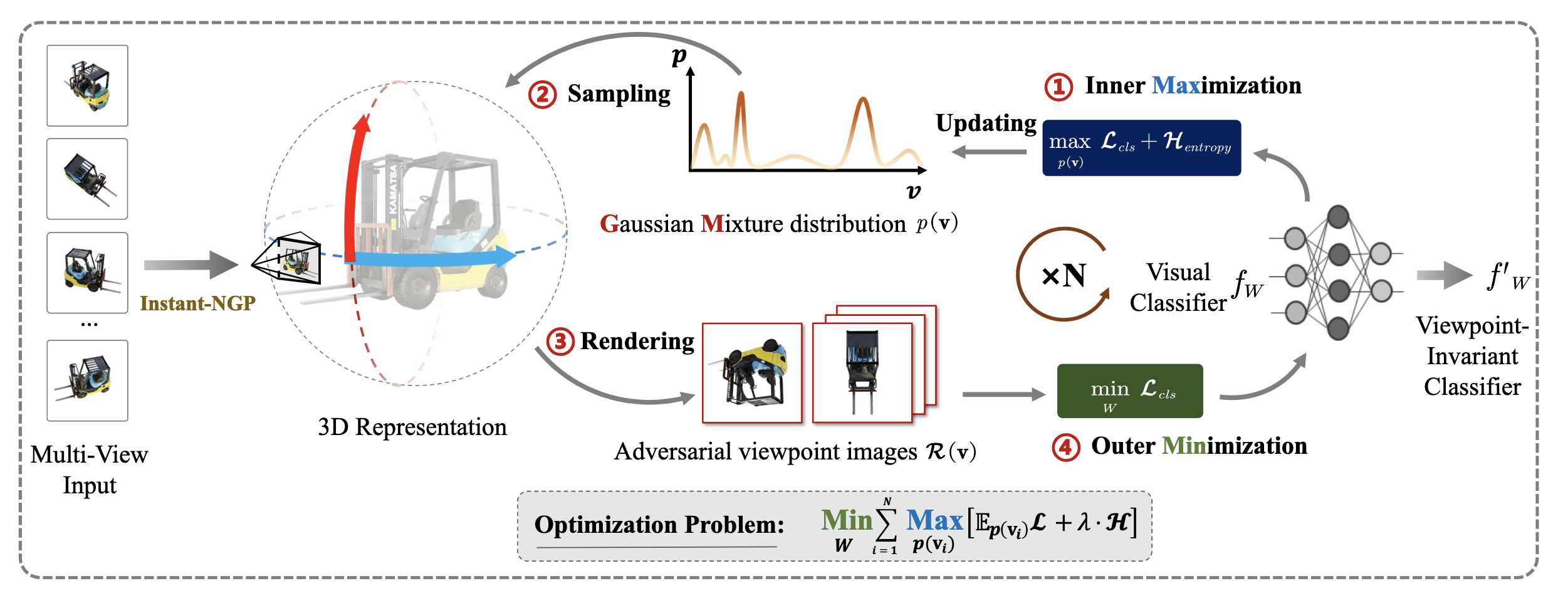
The min-max optimization process of the VIAT framework. The entire process is a game. First, multi-view images of an object are encoded into a continuous Neural Radiance Field (NeRF) representation. Then, in the inner maximization stage, an attacker learns a Gaussian Mixture distribution to find the ‘worst-case’ viewpoint distribution that maximizes the classifier’s loss. Subsequently, in the outer minimization stage, the classifier is trained on images rendered from these worst-case viewpoints to minimize its loss, thereby learning viewpoint invariance. Image source: (Yang et al., 2024)
A key finding of this research is the strong transferability of adversarial viewpoints across objects of the same class.
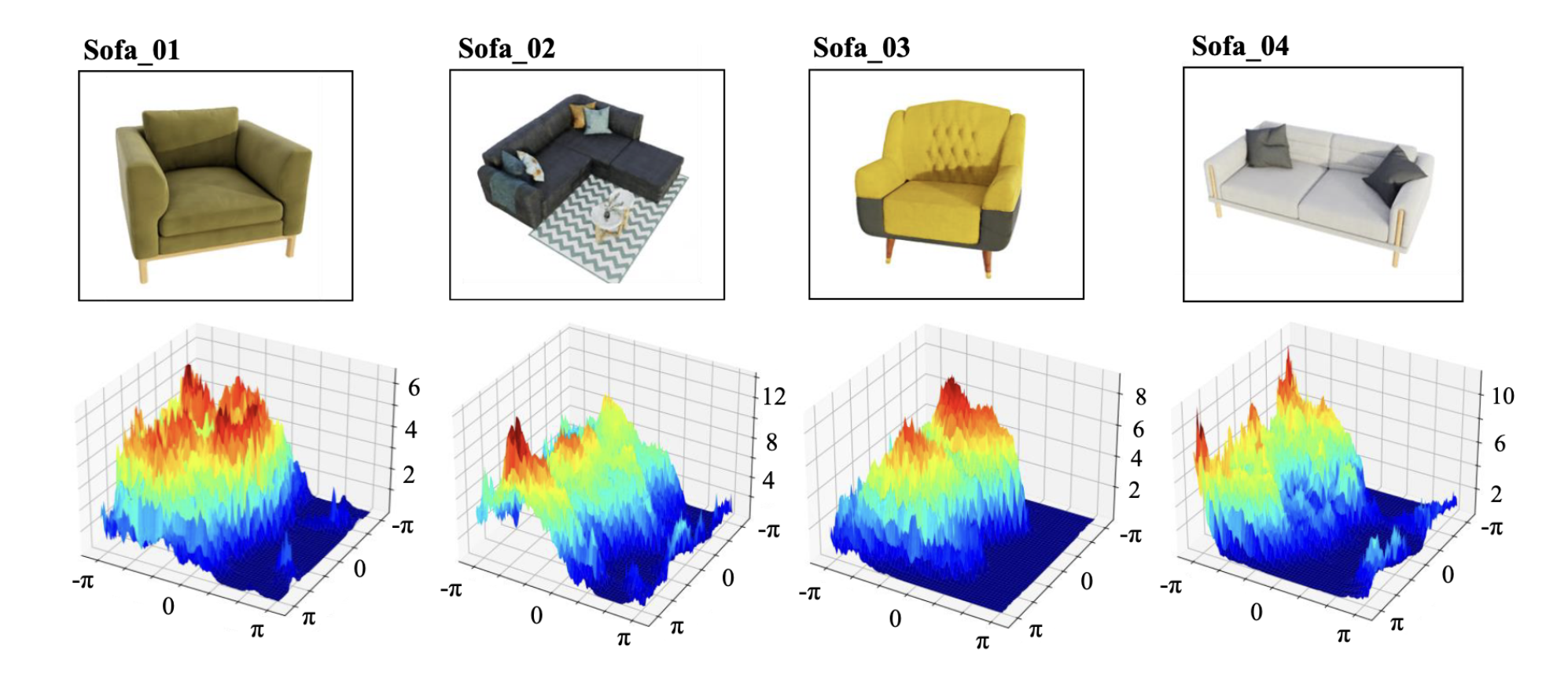
The similarity of loss landscapes for different objects of the same class. Although the four ‘sofa’ objects differ significantly in appearance, their respective loss landscapes are surprisingly similar. The high-loss ‘peaks’ and low-loss ‘valleys’ appear in roughly the same locations across all four maps. Image source: (Yang et al., 2024)
This discovery provides the theoretical basis for an efficient training strategy called distribution sharing, where adversarial viewpoint distributions can be shared and reused among different objects within the same class during training, significantly improving efficiency and enhancing the model’s generalization capabilities.
Models trained with the VIAT framework exhibit a qualitative leap in robustness, capable not only of defending against specially designed synthetic attacks but also of generalizing to complex real-world scenarios.

Performance comparison of standard and VIAT models across multiple scenarios. The standard model proves extremely vulnerable to various adversarial viewpoints (whether from synthetic attacks like GMVFool/ViewFool or real-world objects), frequently making errors. In contrast, the VIAT-trained model demonstrates powerful defense capabilities, making correct judgments in the vast majority of cases, proving its robustness has strong generalization ability and practical value. Image source: (Yang et al., 2024)
Similarly, in the autonomous driving domain, Mao et al., 2023 also focused on common physical-world transformations like rotation and translation. These transformations directly alter meaningful attributes of a scene and pose a direct threat to the reliability of multi-sensor fusion systems.
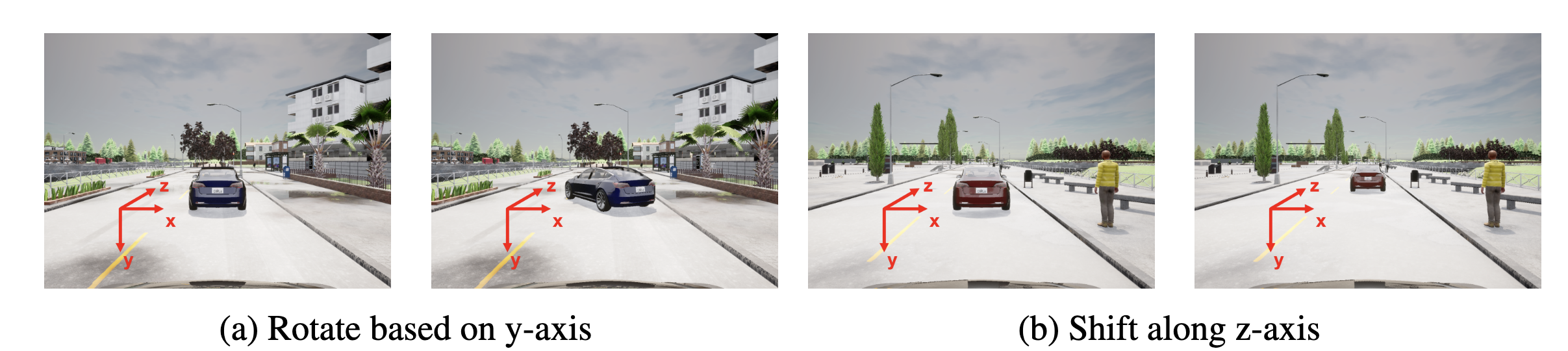
Semantic transformations in an autonomous driving scene. Slight rotations (a) or changes in the distance (b) of the vehicle ahead can significantly alter the input data distribution for sensors (camera and LiDAR), potentially leading to detection failure. Image source: (Mao et al., 2023)
As attack and defense methods become increasingly sophisticated, viewing attacks as isolated events is no longer sufficient. Zhou et al., 2022 were the first to borrow the lifecycle model of Advanced Persistent Threats (APT) from the cybersecurity domain to provide a systematic analysis framework for adversarial attacks.
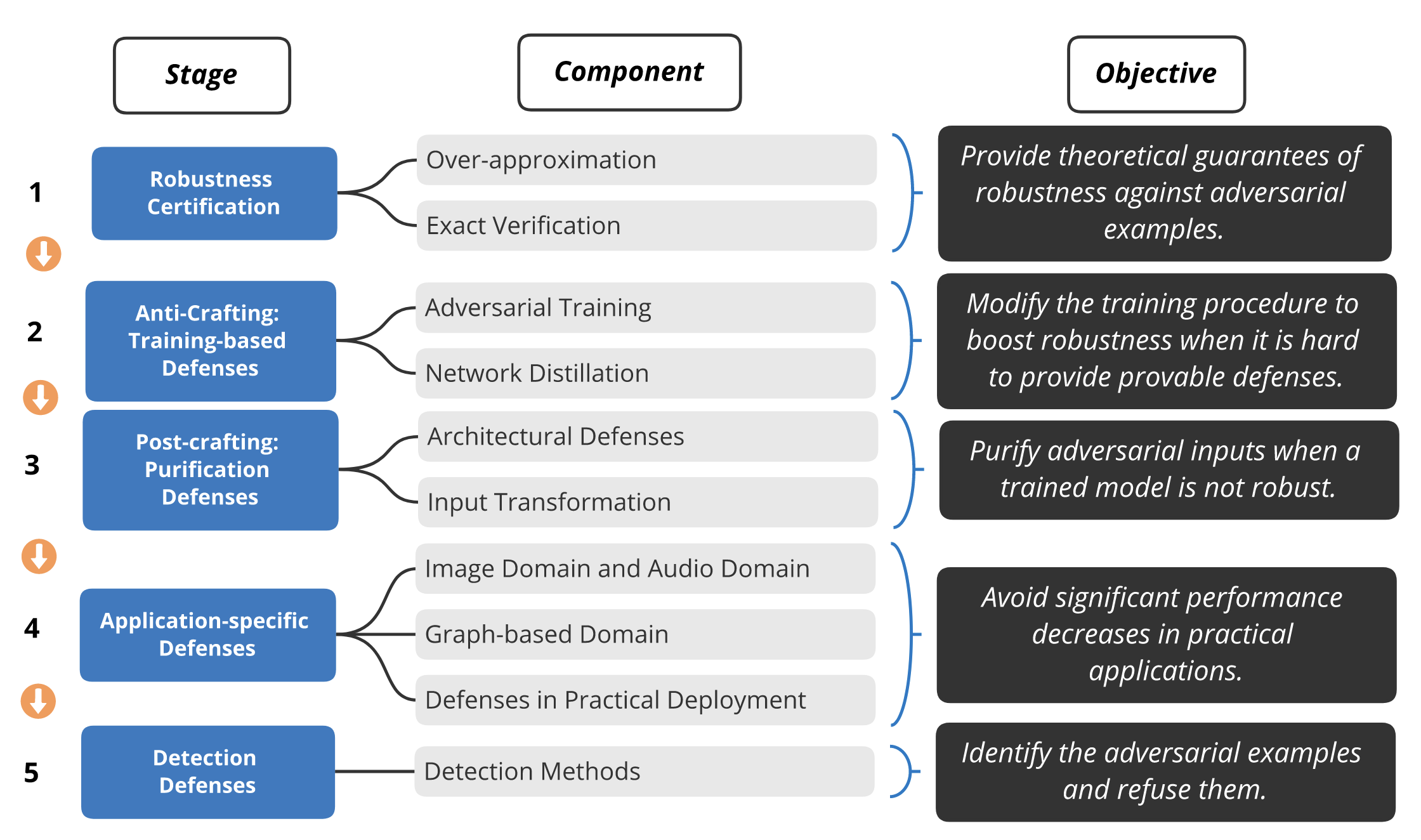
The APT lifecycle model for adversarial attacks. A complex attack can be decomposed into five interconnected stages: 1. Vulnerability Analysis (theoretical reconnaissance), 2. Fabrication (generating basic attacks), 3. Post-Fabrication (enhancing attack transferability or depth), 4. Real Application (applying in the physical world), and 5. Re-evaluation of Imperceptibility (optimizing the perturbation to be more covert). Image source: (Zhou et al., 2022)
This framework integrates disparate attack methods into a unified view, revealing their roles and objectives throughout the attack process.
The most advanced and insidious attacks no longer target the model’s prediction outcome but its explainability—that is, our trust in the model’s decision-making process. The survey by Baniecki & Biecek, 2024 systematically summarizes this emerging field, terming it Adversarial Explainable AI (AdvXAI).
The advent of AdvXAI has opened a new battleground: attacks on model explainability (XAI).
A taxonomy of attacks and defenses in Adversarial Explainable AI (AdvXAI). Attackers can manipulate model explanations through adversarial examples, backdoors, etc., while defenders can counter with model regularization, explanation aggregation, and other techniques. Image source: (Baniecki & Biecek, 2024)
The goal of such attacks is no longer the model’s predictive accuracy but our trust in its decision-making process. An attacker can successfully manipulate a model’s explanation without altering its prediction, thereby providing a false yet seemingly plausible justification to mask the model’s true, potentially biased or flawed, reasoning. This attack on the model’s “mind” presents a novel challenge for deep learning security, warning us against blindly trusting the explanations provided by XAI methods.
Types of Defense
Adversarial Training
We now turn to the most mainstream and effective defense paradigm today: Adversarial Training (AT). The core idea of AT is to introduce adversarial attacks into the training process. By continuously generating adversarial examples that can fool the current model and using them as training data, AT forces the model to learn a decision boundary that is less sensitive to input perturbations. This chapter will start from the basic framework of AT, explore its evolution to address more complex threats, and analyze various advanced strategies aimed at mitigating its inherent performance trade-offs.
The essence of adversarial training, as articulated in surveys by Yuan et al., 2019 and Zhou et al., 2022, is a min-max optimization problem. Its objective can be formally expressed as: $$ \min_{\theta} \mathbb{E}_{(\boldsymbol{x}, y) \sim \mathcal{D}} \left[ \max_{\boldsymbol{\delta} \in \mathcal{S}} \mathcal{L}(\boldsymbol{x} + \boldsymbol{\delta}, y; \theta) \right] $$ This framework involves a two-stage game. First is the Inner Maximization, where for fixed model parameters $\theta$ and input $\boldsymbol{x}$, an adversarial perturbation $\boldsymbol{\delta}$ is found within the set $\mathcal{S}$ to maximize the loss function $\mathcal{L}$, generating the most effective attack sample. This is followed by the Outer Minimization, where the model parameters $\theta$ are adjusted to minimize the expected loss on these worst-case samples, thereby enhancing the model’s robustness. Although this framework is powerful, traditional AT often focuses only on defending against single, pixel-based $L_p$-norm attacks, which falls short of the complex and varied threat models in the real world.
To address real-world composite perturbations, which are often multi-dimensional, the work by Laidlaw et al., 2021 extends adversarial training from defending against single perturbations to defending against combinations of multiple semantic perturbations, proposing the Generalized Adversarial Training (GAT) framework. A core insight of their research is that in composite attacks, the order of attacks is crucial.

The impact of attack order on the effectiveness of composite attacks. As shown, simply moving the ℓ∞ attack from the first step to the fourth step of the attack sequence can turn a previously ineffective composite attack into a successful one, causing the model to misclassify a ‘warplane’ as a ‘wing.’ Image source: (Laidlaw et al., 2021)
To this end, the GAT framework utilizes a Composite Adversarial Attack (CAA) method that automatically learns the optimal attack sequence to generate more powerful adversarial examples. By training in this more severe and realistic attack environment, GAT enables the model’s decision boundary to become smoother to multiple types of perturbations, thus achieving stronger general robustness.
Despite its effectiveness, the most criticized drawback of adversarial training is that it often comes at the cost of the model’s standard accuracy on clean data. To mitigate this “accuracy-robustness trade-off,” researchers have proposed several ingenious balancing strategies. One such solution, presented by Chen et al., 2023, is the B-MTARD framework. This method moves beyond a single model and introduces two expert teachers for knowledge distillation.
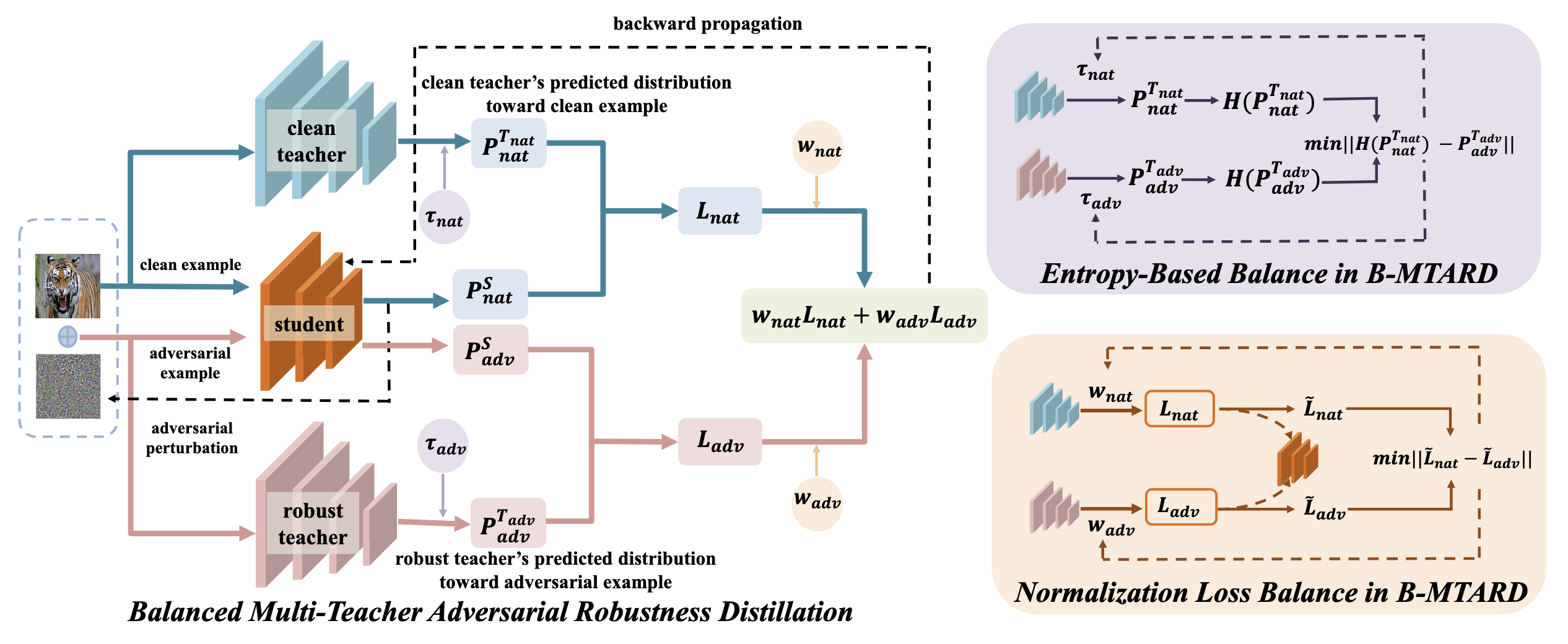
The multi-teacher distillation framework of B-MTARD. The framework has a student model learn simultaneously from two teachers: a clean teacher, who imparts knowledge on achieving high standard accuracy, and a robust teacher, who passes on experience in adversarial robustness. To address imbalances between the teachers’ ’teaching styles’ and the student’s ’learning pace,’ the framework innovatively designs two dynamic balancers: an entropy-based balancer to unify the ‘knowledge intensity’ of the teachers, and a normalized loss balancer to coordinate the student’s ’learning progress.’ Image source: (Chen et al., 2023)
Through this intelligent collaborative teaching, the student model can effectively assimilate the strengths of both, achieving a better balance between accuracy and robustness.
Another perspective on solving the trade-off comes from Liu et al., 2023, which approaches the problem from the angle of model complexity. Their work finds that a key intrinsic metric, $\Gamma_{ce}$ (measuring the confidence contrast between “mastered” and “unmastered” samples), has a phased relationship with the model’s generalization gap: a positive correlation in the early stages of training and a negative one in the later stages. Based on this observation, they designed a “phased” training strategy: in the early phase, regularization is used to decrease $\Gamma_{ce}$ to build a good generalization foundation, while in the later phase, $\Gamma_{ce}$ is increased to “reclaim” lost standard accuracy. This dynamic adjustment allows the model to focus on the most appropriate optimization target at different training stages.
Furthermore, Zhao et al., 2023 formalize the trade-off as a principled constrained optimization problem and solve it using the Lagrangian dual method. The core idea is to strictly constrain the embeddings generated by the fine-tuned model on clean data to remain close to those of the original pre-trained model, while simultaneously fine-tuning for adversarial robustness.
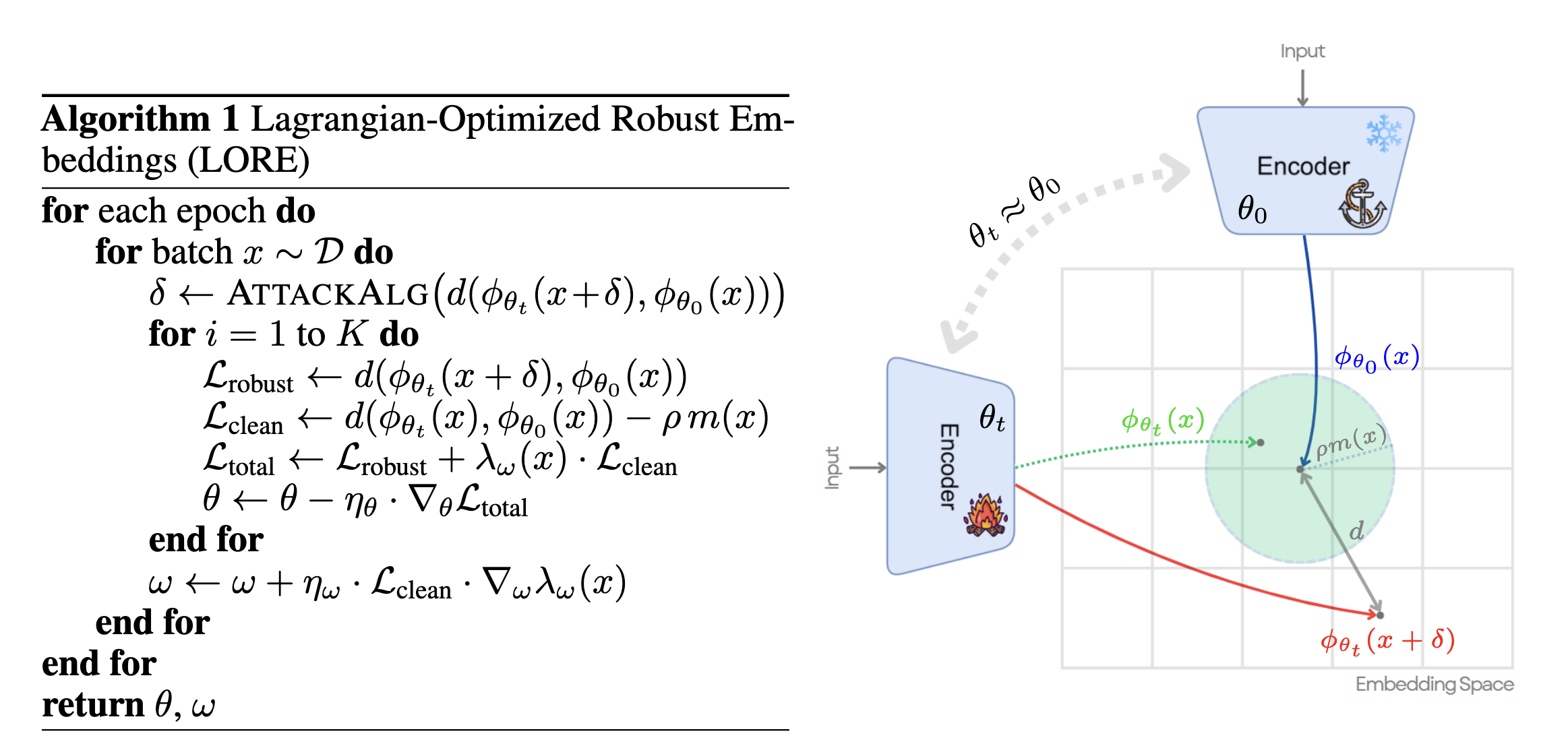
The core concept and optimization framework of LORE. As shown on the right, the optimization process of LORE is constrained by a ‘safe zone’ centered around the original model’s embedding. The fine-tuned model’s embedding on clean inputs must remain within this region. Meanwhile, the training objective is to pull the embedding of the attacked input back to the original model’s anchor point. Image source: (Zhao et al., 2023)
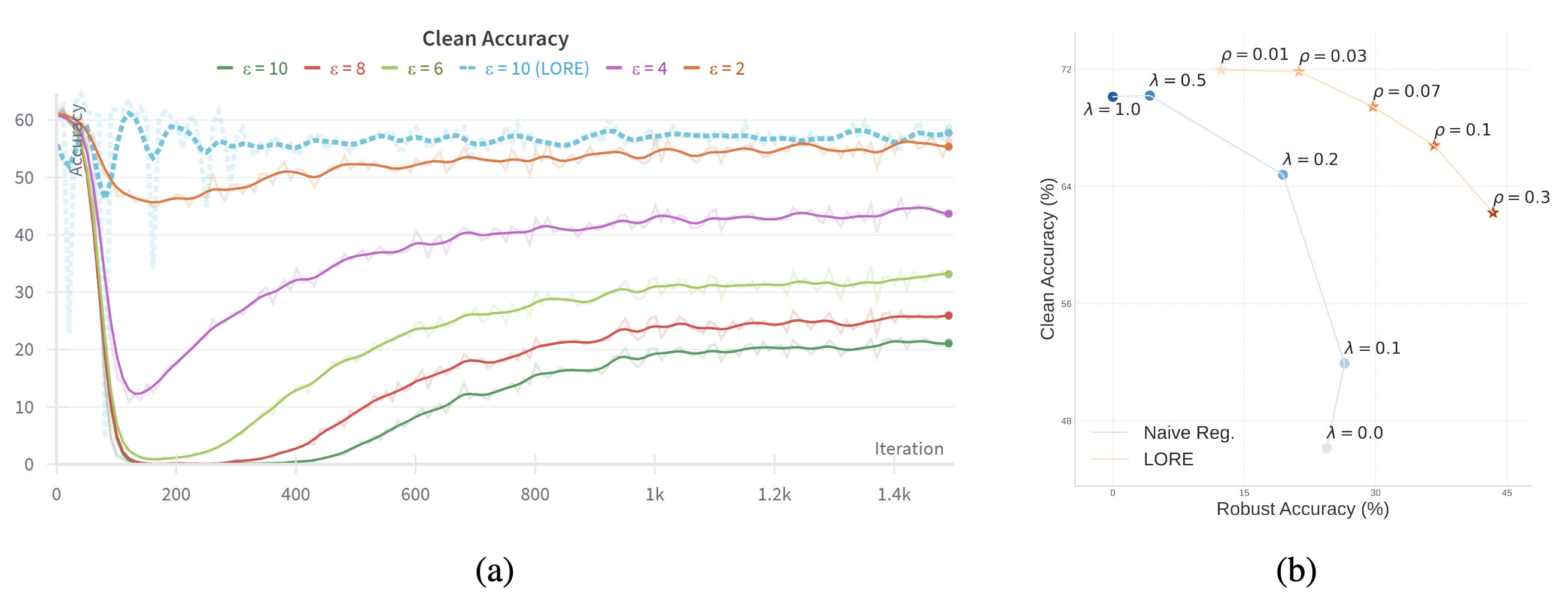
LORE’s improvements in training stability and performance trade-off. This constrained mechanism yields significant benefits. LORE (blue dashed line) completely avoids the catastrophic collapse of standard accuracy seen in traditional adversarial fine-tuning (solid lines) during the initial training phase. LORE (orange starred line) also achieves a better Pareto frontier between robust accuracy and standard accuracy compared to naive regularization methods (blue dotted line). Image source: (Zhao et al., 2023)
By transforming the trade-off from a simple weighted sum into a principled, constrained optimization problem, LORE provides a powerful and elegant framework for maximizing the preservation of a model’s original knowledge and performance while enhancing its robustness.
Data-Centric Defenses
Beyond directly optimizing the model to counter attacks through adversarial training, another powerful and complementary defense paradigm is data-centric. The core idea is that instead of merely forcing the model to learn in a difficult environment, we can directly provide it with higher-quality, more diverse, and more challenging training data, compelling it to learn more generalizable features.
The work by Lee et al., 2022, IPMix, no longer settles for single-dimensional transformations but pioneeringly fuses image-level, patch-level, and pixel-level augmentations within a parallel, chain-mixed framework.

A visual comparison of common data augmentation methods. From simple CutOut and Mixup to the more complex PixMix. Image source: (Lee et al., 2022)
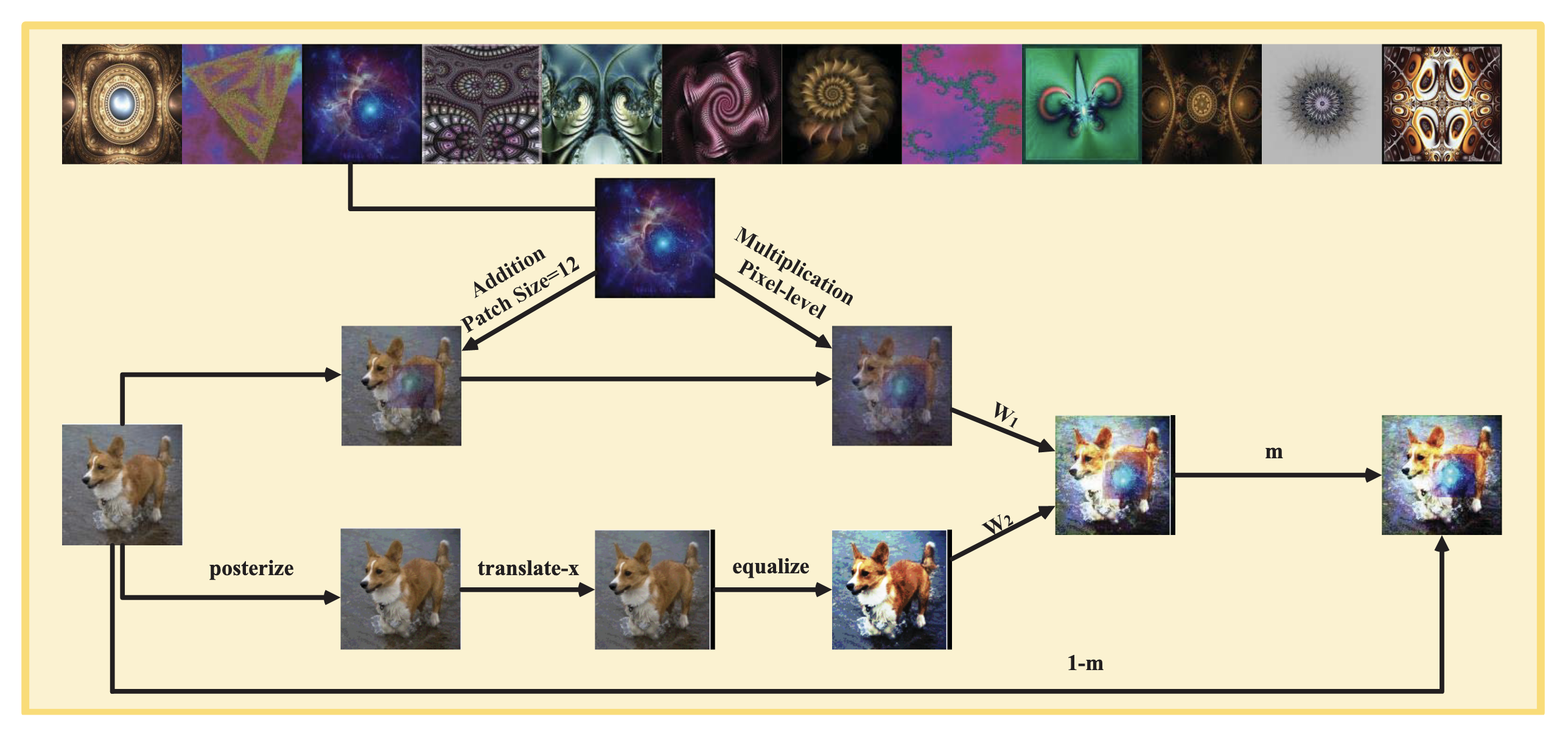
The Chain-Mixed Framework of IPMix. At the heart of IPMix is an elegant parallel processing workflow. The original image is routed into multiple parallel ‘augmentation chains.’ Some chains apply traditional image-level transformations, while others mix the image with external synthetic images at the pixel or patch level. These variously ‘prepared’ images are finally fused and mixed with the original image via a skip connection to ensure core semantics are preserved. Image source: (Lee et al., 2022)
The essence of this method lies in the granularity of its information fusion. It moves beyond simple mathematical operations to design more sophisticated mixing mechanisms, creating unprecedented pixel combinations to maximally enrich the training data distribution.
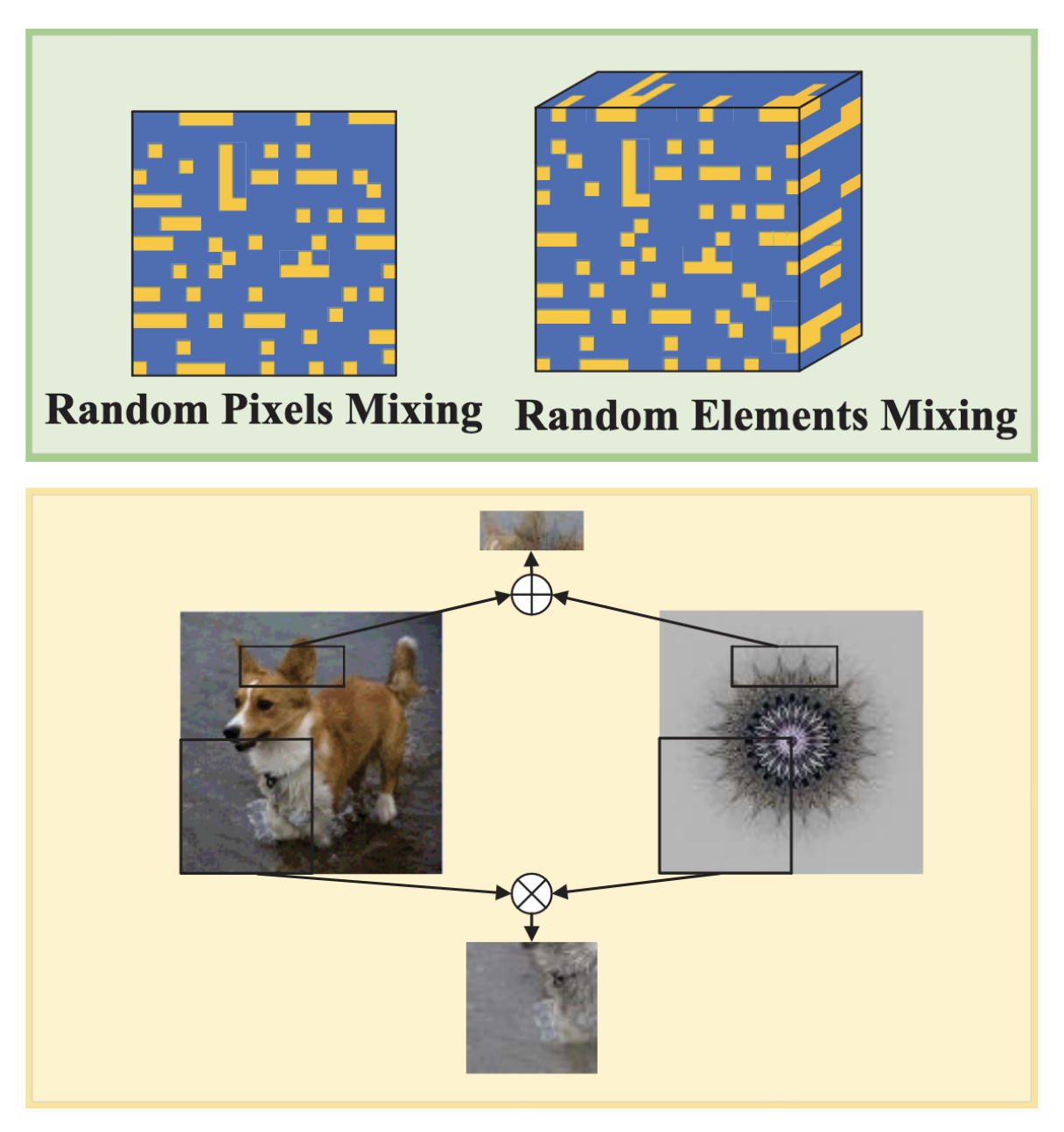
The fine-grained mixing operations of IPMix. IPMix uses random masks at the pixel and element levels to ‘weave’ the information from two images together. It can also perform targeted mixing in specific regions (such as ‘scar-like’ or ‘block-like’ patterns) to simulate various local occlusions and artifacts. Image source: (Lee et al., 2022)
The effect of this complex augmentation strategy is significant, as it reshapes the model’s internal feature space.
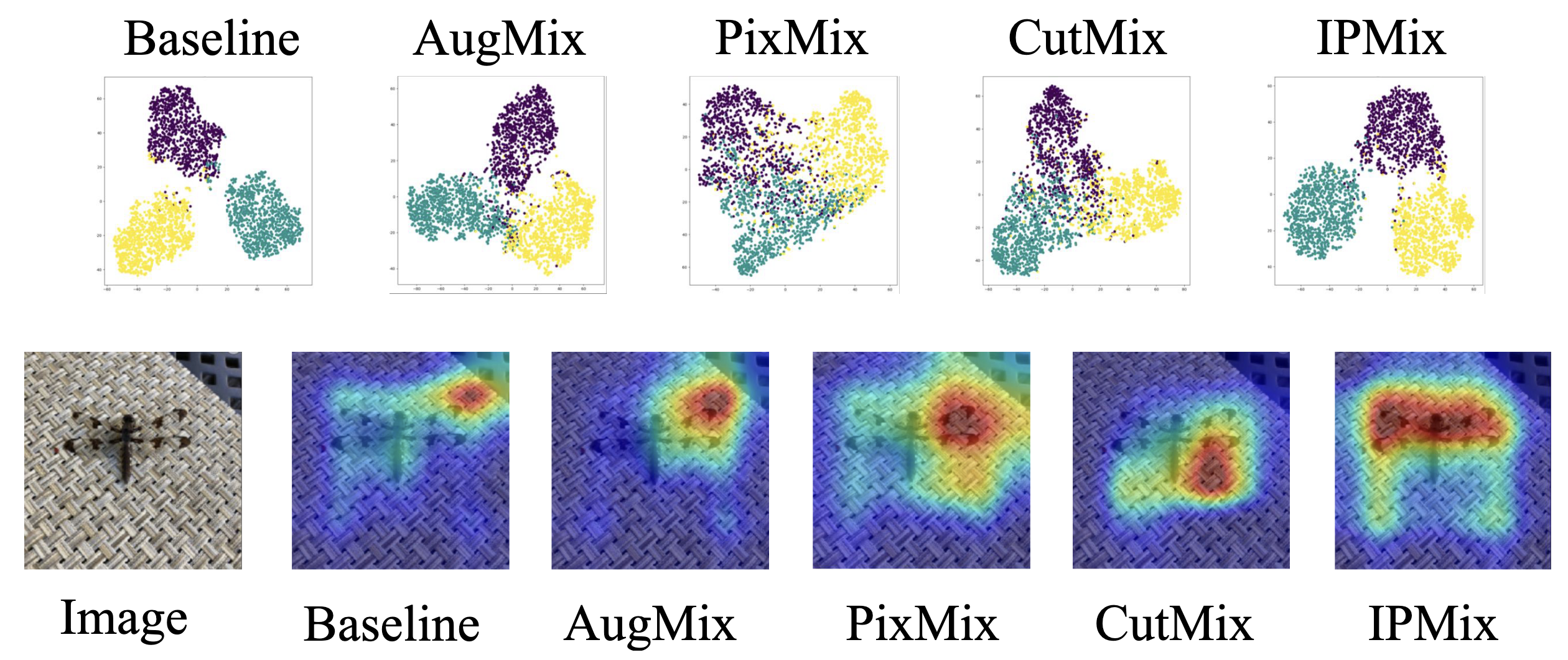
Improved feature space and attention mechanism after IPMix training. The t-SNE visualization in the upper part shows that after IPMix training, the feature clusters for different classes become more compact intra-class and more separated inter-class. Meanwhile, the Grad-CAM heatmaps in the lower part reveal that the baseline model’s attention is entirely captured by background textures, whereas the IPMix-trained model can precisely and completely cover the subject (a dragonfly) itself. Image source: (Lee et al., 2022)
In contrast to IPMix’s pursuit of “all-encompassing” complexity, the work by Zhang et al., 2023 approaches the problem from the perspectives of “efficiency” and “universality,” proposing a plug-and-play UAA framework. Its core idea is to decouple the expensive process of generating adversarial perturbations from the model training pipeline.
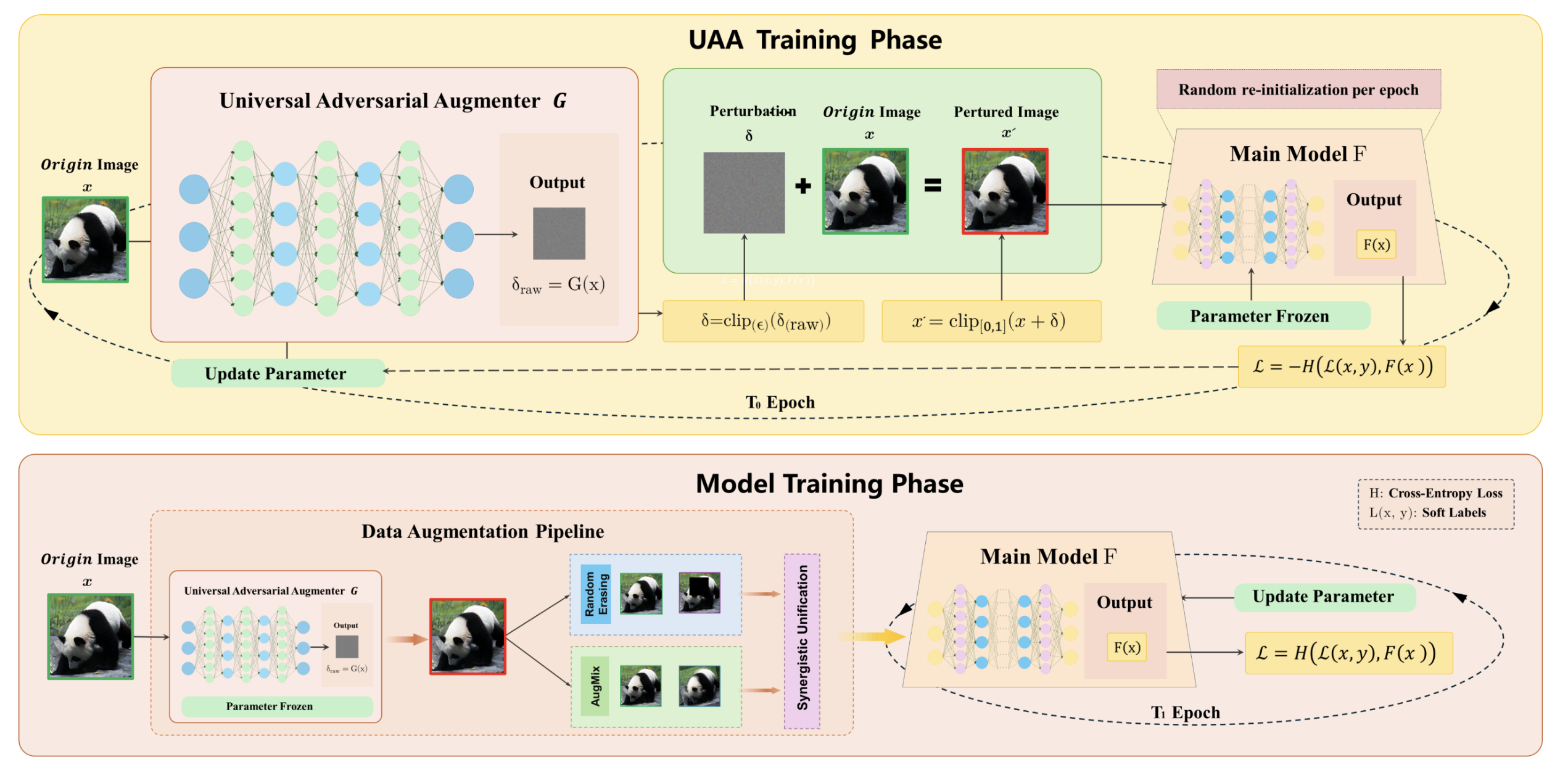
The two-stage decoupled framework of UAA. In the first stage (top), a generator G capable of producing ‘universal’ adversarial perturbations is trained offline. To prevent G from overfitting, the target classifier’s parameters are randomly re-initialized in each epoch. In the second stage (bottom), this pre-trained, fixed G serves as an efficient data augmentation tool, seamlessly integrated into the main model’s training process. Image source: (Zhang et al., 2023)
However, does simply increasing the quantity and complexity of data solve the problem of insufficient robustness?
Research from Wang et al., 2023 emphasizes the “quality” of augmented data. Their results surprisingly show that using more advanced generative models (like EDM) to create synthetic data is far more effective at improving model adversarial robustness than many traditional, distortion-based augmentation methods. A key finding of this study is that when training with a massive amount of high-quality generated data, the phenomenon of “robust overfitting” (where test robustness starts to decrease after peaking during training) almost completely disappears. To combat this, “early stopping” is typically required. However, with large-scale, high-quality data from EDM, robust overfitting is virtually eliminated, allowing the model’s test robustness to improve steadily throughout training. This means one can train for longer to achieve better performance without carefully searching for the optimal stopping point. The paper also investigated the impact of generated data quality (measured by FID score) on model performance. The results clearly indicate that the lower the FID score of the generated data (i.e., the higher the quality), the higher the standard and robust accuracy of the final trained model.
On the topic of how data augmentation should be done, different researchers hold almost opposing views. Research from Bai et al., 2023 uncovered a startlingly counter-intuitive phenomenon: in the specific paradigm of adversarial training for Vision Transformers (ViTs), widely-used strong data augmentations (like MixUp, CutMix) are not only unhelpful but actually detrimental.
This finding fundamentally challenges the conventional wisdom that “stronger augmentation leads to better robustness.” The root cause lies in a conflict between two mechanisms for “making the task harder”—strong data augmentation and adversarial perturbation—which leads to “overcorrection” or a “loss of training focus,” thereby undermining the learning of robustness.
First, adversarial training is itself a very strong form of regularization. It requires the model not only to classify a single data point correctly but also to maintain a stable prediction within a high-dimensional neighborhood around that point (e.g., a small ball of radius ε). This is already a highly challenging optimization target. Strong data augmentation, such as MixUp, which creates semantically ambiguous mixed images that do not exist in the real world, is also a powerful regularization technique. When these two potent regularization methods are combined, the training task becomes exceptionally difficult. It’s like asking a student to solve an extremely complex math problem written in two mixed languages simultaneously; the student is likely to become confused by having to deal with both difficulties at once and may end up mastering neither.
Second, adversarial training is a min-max process, with its core being the inner “maximization” step—finding the “strongest” adversarial example that maximizes the loss for the current model at each training step. This is like finding a high-quality “sparring partner” for the model. However, strong data augmentation undermines the quality of this “sparring partner.” The starting point becomes ambiguous: When training begins with an image created by mixing two pictures with MixUp, this starting point has already deviated from the clean, real data distribution. The gradient signal obtained from such a “blurry” starting point to find the most confusing perturbation direction is far less clear and effective than that from a clean sample. The effectiveness of the attack is reduced: The paper’s experiments show that when using the “light recipe” (without strong data augmentation), the attacks during training become more effective. This means the model faces “genuine” strong attacks in every round. Conversely, with the “standard recipe” using strong data augmentation, the attack effectiveness is significantly diminished. As the attacks in training are weakened, the model naturally incurs a lower loss on these “watered-down” adversarial examples, leading to an apparently high “robust accuracy” on the validation set. However, this is a false, overestimated robustness. When the model, after training, is confronted with a truly powerful standard attack (like AutoAttack) generated from a clean sample, this deceptive defense crumbles.
This contradiction points to a core dilemma in data augmentation: how can we harness the benefits of diversity from high-intensity augmentations without introducing destructive noise to the model?
To address this, the work by Park et al., 2023 shifts the focus from how to transform images to how to assign appropriate “supervisory signals” to the transformed images. Instead of assigning a rigid, 100% confidence hard label to all augmented samples—regardless of their distortion level—it introduces a more intelligent and adaptive labeling paradigm. The confidence of the label assigned to augmented data should correlate with the degree of “distortion.” Augmented samples closer to the original data should have higher label confidence, while those that are further away and more severely distorted should have lower confidence.
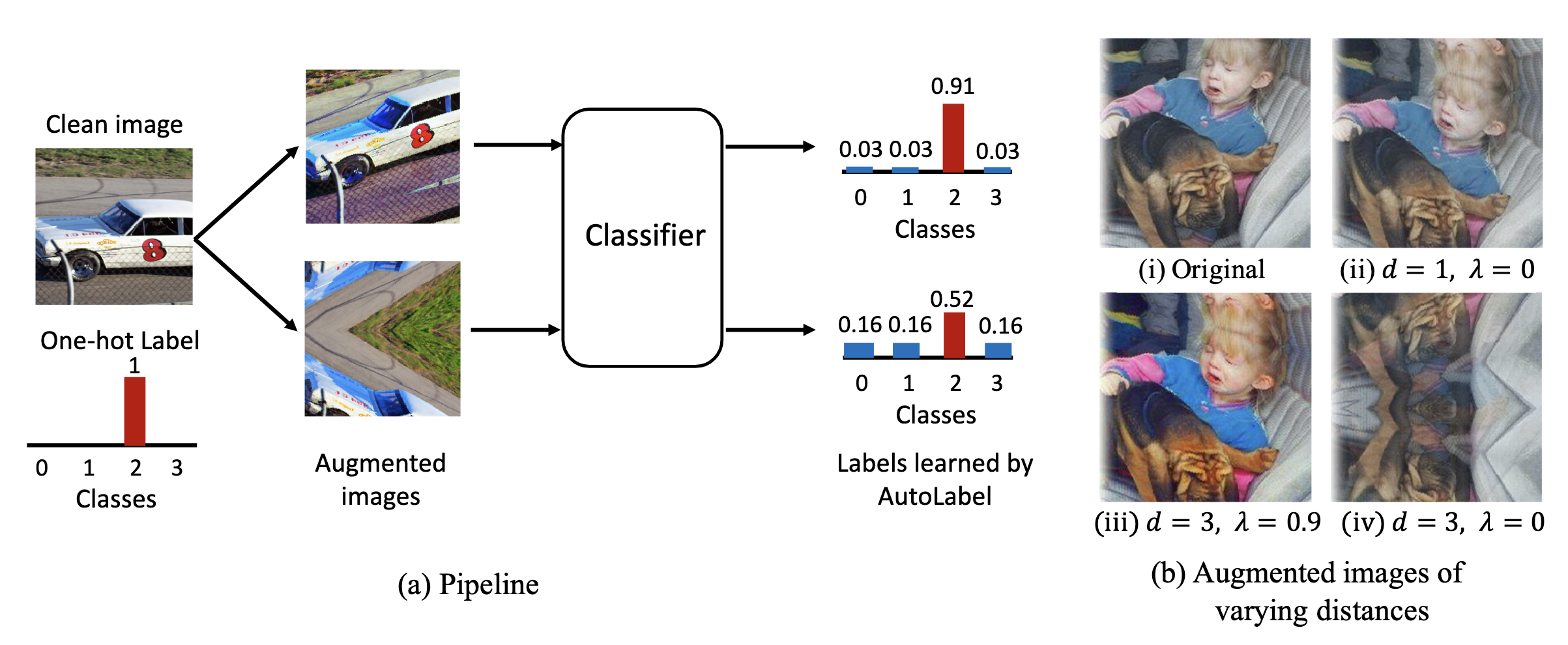
The core idea and workflow of AutoLabel. As shown in Figure (a), the process is intuitive. For an augmented image that is similar to the original and only slightly distorted (top), the learned label confidence remains high (0.91). But for a severely distorted image that is difficult even for humans to recognize (bottom), the learned label confidence drops significantly (0.52). Image source: (Park et al., 2023)
This adjustment is achieved through a feedback mechanism. AutoLabel defines a “transformation distance” based on the augmentation parameters, which quantifies the degree of image distortion. As shown in Figure (b), the lower the mixup ratio and the longer the augmentation chain, the greater the transformation distance. AutoLabel uses this distance to dynamically update the label confidences for training samples in different “distance bins” by evaluating the model’s calibration error (ECE) on a clean validation set after each training epoch.
Certified Defenses
The adversarial training and data augmentation methods we’ve discussed so far fall under the category of Empirical Defenses. These methods aim to improve a model’s performance against known types of attacks by introducing diverse or adversarial data during training. Their effectiveness is typically empirically verified by measuring test accuracy against specific attack algorithms like PGD or AutoAttack. However, empirical defenses have a fundamental limitation: they cannot guarantee protection against new, more powerful attacks that may emerge in the future. A model that appears robust on current benchmarks could still be compromised by an adaptive attack designed specifically for it.
To overcome this uncertainty, the research community has increasingly turned to a more rigorous and challenging goal: Certified Defenses.
The objective of certified defenses, as articulated in works like the survey by Zhou et al., 2022, is not simply to improve performance against specific attacks, but to provide a mathematical, provable guarantee of robustness for a model’s predictions.
This guarantee is attack-agnostic. It does not depend on the specific algorithm used by an attacker to generate an adversarial example. Instead, it defines a perturbation set $\mathcal{S}$ around an original input $\boldsymbol{x}$ (e.g., an $L_\infty$-norm ball of radius $\epsilon$) and mathematically proves that for all possible inputs $\boldsymbol{x}’ \in \mathcal{S}$, the model’s prediction will remain unchanged.
Formally, a certified defense aims to verify the truth of the following statement: $$ \forall \boldsymbol{x}’ \in \mathcal{S}, \quad \arg\max_j f(\boldsymbol{x}’)_j = \arg\max_j f(\boldsymbol{x})_j $$
This paradigm shift offers the highest level of security assurance for a model. It is no longer an endless “arms race” between attacks and defenses, but a means of establishing an absolute safety boundary for the model’s behavior. Once certified, we can be confident that any perturbation within this boundary, no matter how cleverly designed, cannot alter the model’s prediction.
The technical means to achieve such guarantees fall into two main categories: complete verification methods, such as Mixed-Integer Linear Programming (MILP), which provide exact answers but are computationally expensive and difficult to scale to large networks; and incomplete verification methods, like convex relaxation and randomized smoothing, which provide a lower bound on robustness. While potentially conservative due to approximation, they are more computationally efficient and practical.
Among incomplete verification methods, Randomized Smoothing (RS) has become one of the most practical and widely studied techniques due to its scalability and model-agnostic nature. Its core idea is to construct a smoothed classifier by injecting random noise (typically Gaussian) at the input and using a “majority vote” principle. This smoothed classifier can provide a probabilistic, yet provable, robustness radius for its predictions. However, the basic RS framework faces several challenges, and recent research has focused on deepening its theoretical understanding, overcoming its intrinsic limitations, and expanding its applications.
It has long been established in practice that for randomized smoothing to be effective, the underlying base classifier must be trained on noise-augmented data. However, this practice lacked solid theoretical support for a long time.
The work by Li et al., 2023 provides a deep analysis of this phenomenon, revealing that noise-augmented training is not universally beneficial. The study introduces the concept of “interference distance” to describe the degree of separation between decision regions of the same class in the data distribution. A large interference distance means the decision regions are sparsely distributed and isolated from each other, while a small interference distance means they are densely packed and close together.
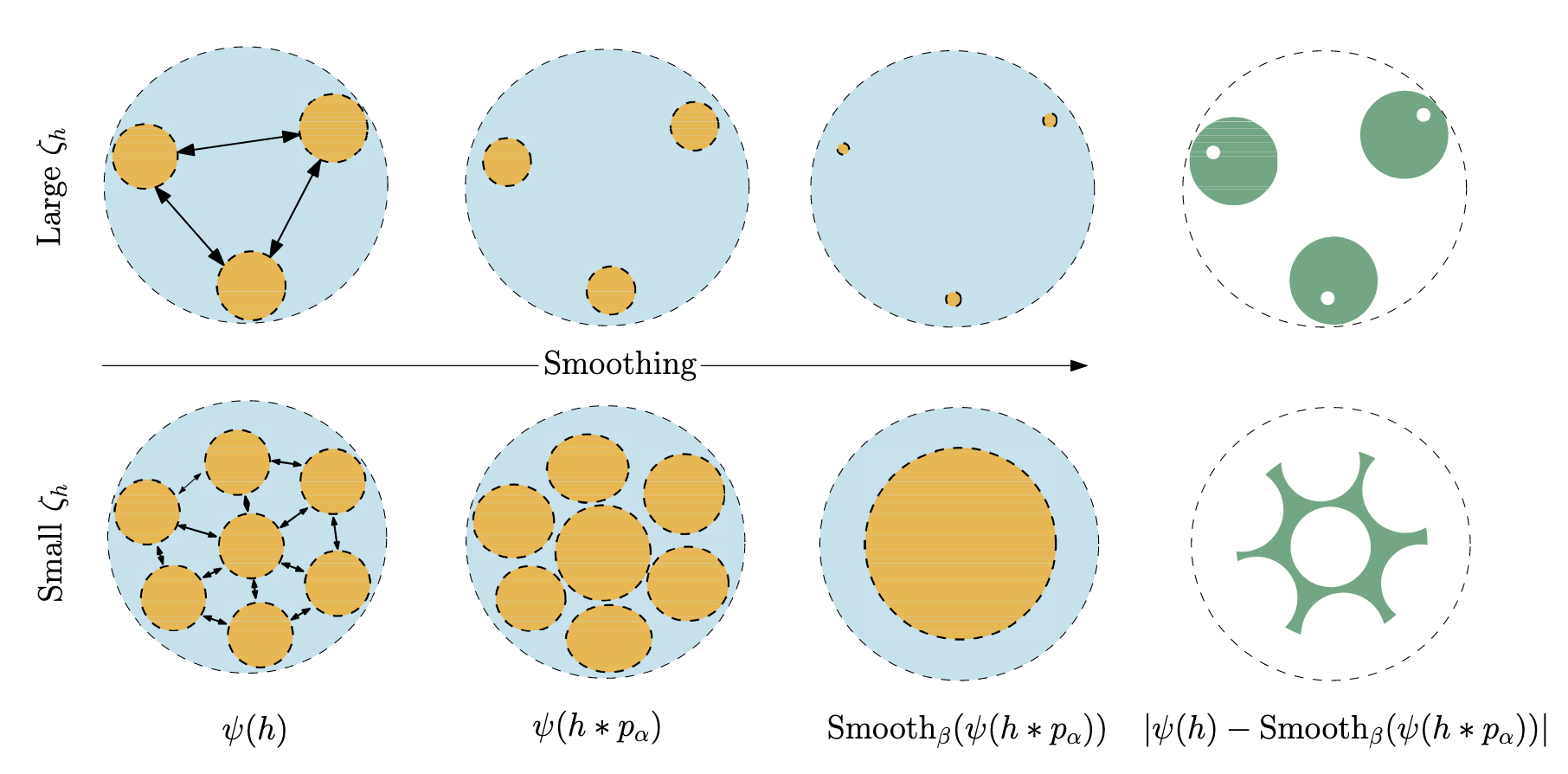
The effect of interference distance on noise-augmented training. When the interference distance is large (top row), both noise-augmented training (second column) and the subsequent smoothing operation (third column) cause the decision regions (orange) to continuously ‘shrink,’ leading to significant performance degradation. In contrast, when the interference distance is small (bottom row), the training noise helps to ‘merge’ adjacent decision regions into a larger, more stable whole, resulting in better performance after smoothing. Image source: (Li et al., 2023)
This research theoretically proves that the effectiveness of noise-augmented training is closely related to this “interference distance”: it can be detrimental for distributions with a large interference distance, but essential for those with a small one. This not only explains why the method works well on real-world datasets like CIFAR-10 but also, more importantly, indicates that the noise level for training and the noise level for certification do not need to be the same. Tuning them as independent hyperparameters can lead to superior performance.
One of the most critical weaknesses of randomized smoothing is the Curse of Dimensionality. As the input dimension $d$ increases, the certified radius rapidly decays at a rate of $1/\sqrt{d}$, severely limiting its application to high-dimensional data like high-resolution images.
To overcome this challenge, Kumar et al., 2023 proposed Dual Randomized Smoothing (DRS). The core idea is to decompose a high-dimensional smoothing problem into multiple parallel low-dimensional problems.
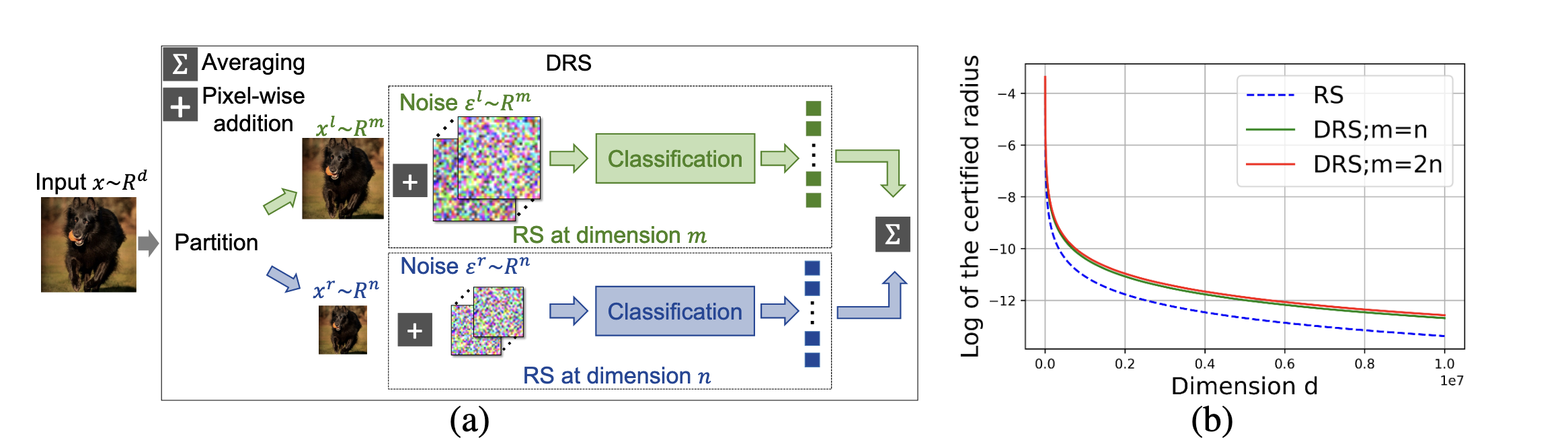
The core idea and theoretical advantage of DRS. As shown in (a), DRS partitions a high-dimensional input into two lower-dimensional subspaces and applies randomized smoothing to them independently. The theoretical analysis in (b) shows that the certified radius upper bound for DRS (solid green and red lines) is significantly higher than that of traditional RS (dashed blue line), and this advantage becomes more pronounced as the dimensionality increases. Image source: (Kumar et al., 2023)
Through this “divide and conquer” strategy, the decay rate of the DRS robustness radius upper bound is improved to $(1/\sqrt{m} + 1/\sqrt{n})$ (where $m+n=d$), effectively mitigating the curse of dimensionality.
To translate this theoretical advantage into a practical algorithm, the study proposes a concrete implementation workflow. The process begins by partitioning an input image $\boldsymbol{x} \in \mathbb{R}^d$ into two lower-dimensional sub-images, $\boldsymbol{x}^l \in \mathbb{R}^m$ and $\boldsymbol{x}^r \in \mathbb{R}^n$, using two non-overlapping downsampling operators, $\pi_l$ and $\pi_r$. Subsequently, randomized smoothing is performed on these two sub-images in parallel.
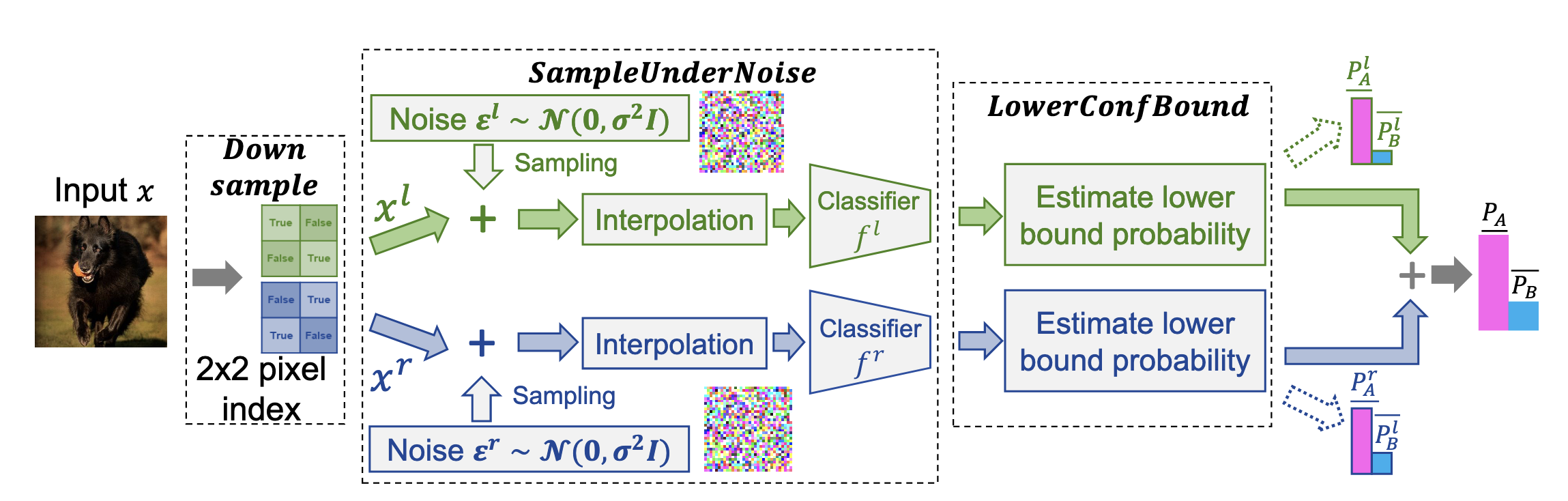
The implementation workflow of Dual Randomized Smoothing (DRS). This flowchart details the steps of DRS, including downsampling using 2x2 pixel indexing, parallel noise injection, interpolation, and classification of sub-images, estimating probability lower bounds via statistical methods, and finally aggregating the results. Image source: (Kumar et al., 2023)
In the workflow shown in Figure 20, two parallel smoothed classifiers, $g_l$ and $g_r$, are constructed. For the left path, the probability of the smoothed classifier $g_l$ predicting class $c$, denoted as $p_c(g_l, \boldsymbol{x}^l)$, is estimated by extensive sampling of the base classifier $f^l$ on the sub-image with added Gaussian noise $\boldsymbol{\epsilon}^l \sim \mathcal{N}(0, \sigma^2 \boldsymbol{I}_m)$. A key engineering detail is that since the downsampled sub-images are smaller, they must be enlarged back to the original size via Interpolation to be processed by the base classifier, which was trained on full-size images.
During the certification phase, to obtain a provable guarantee, the algorithm does not directly use the prediction frequency as the probability. Instead, it utilizes statistical tools (like the Clopper-Pearson interval) to compute a confidence lower bound for the probabilities of the top-1 class $c_A$ and top-2 class $c_B$ for each sub-classifier, $\underline{p_A^l}$ and $\underline{p_A^r}$. Finally, the prediction of the DRS classifier $g_{DRS}$ is determined by aggregating these two independent probability distributions, with the total probability lower bound for the top class $c_A$ being $\underline{p_A} = \underline{p_A^l} + \underline{p_A^r}$. This aggregated probability lower bound $\underline{p_A}$ is then used to calculate the certified radius $R$ for the entire system in the original $d$-dimensional space: $$ R = \sigma \Phi^{-1}(\underline{p_A}) $$ where $\Phi^{-1}$ is the inverse cumulative distribution function of the standard normal distribution. In this manner, DRS provides a computationally feasible and theoretically superior solution for the certified robustness of high-dimensional inputs.
Another issue with traditional RS is its often rigid trade-off between robustness and accuracy. To defend against more realistic attacks that can only perturb a subset of entities, Duan et al., 2023 proposed the Hierarchical Randomized Smoothing framework. Its core idea is “targeted noising.”
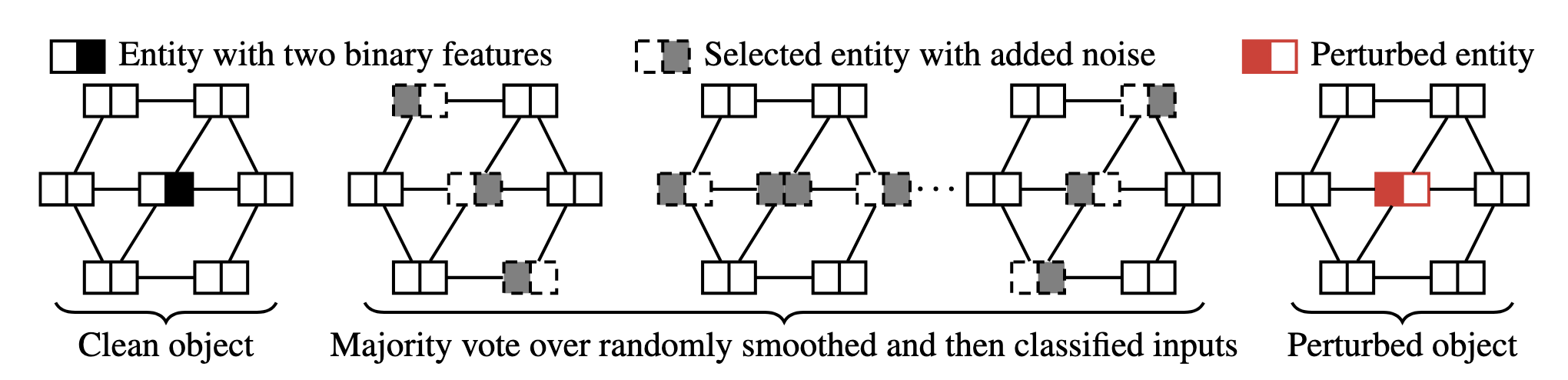
The workflow of Hierarchical Randomized Smoothing. Instead of adding noise to all entities, this method proceeds in two steps: first, it randomly selects a subset of entities (nodes with dashed borders); then, it adds noise only to the selected entities. Image source: (Duan et al., 2023)
To achieve efficient certification, the method innovatively “appends” a selection indicator information as an extra channel or feature dimension to the original data. This technique of encoding meta-information as part of the data greatly simplifies the mathematical proof, allowing the framework to flexibly integrate almost any existing smoothing distribution.
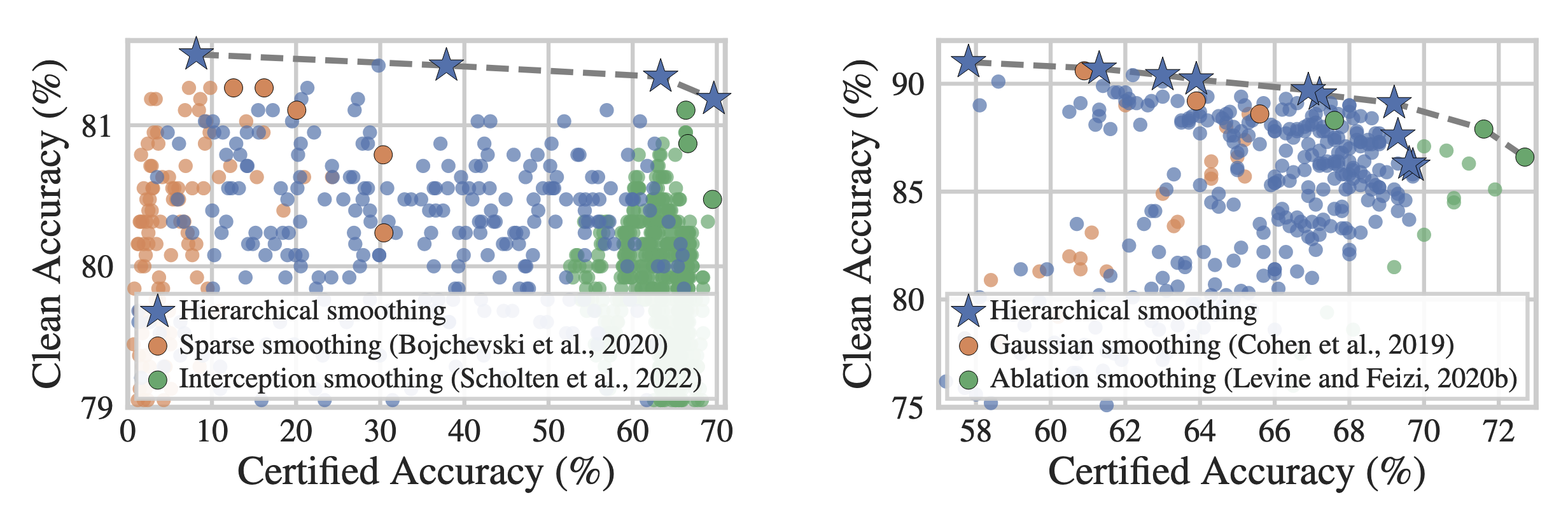
The advantage of hierarchical smoothing in the robustness-accuracy trade-off. Hierarchical smoothing (blue stars) significantly outperforms traditional additive noise (orange circles) and random erasing (green circles) on the Pareto frontier of robustness versus accuracy, offering a series of superior trade-off solutions. Image source: (Duan et al., 2023)
Basic RS is primarily designed for classification tasks. Extending it to more complex outputs, such as semantic segmentation, is a crucial frontier of research.
Chiang et al., 2023 address the issue of high abstain rates in semantic segmentation certification with Adaptive Hierarchical Certification. When a model’s prediction for a pixel wavers between semantically related classes (e.g., “car” and “truck”), traditional methods would “abstain.” This method, however, adaptively relaxes the requirement, certifying it to a coarser parent class (e.g., “vehicle”).
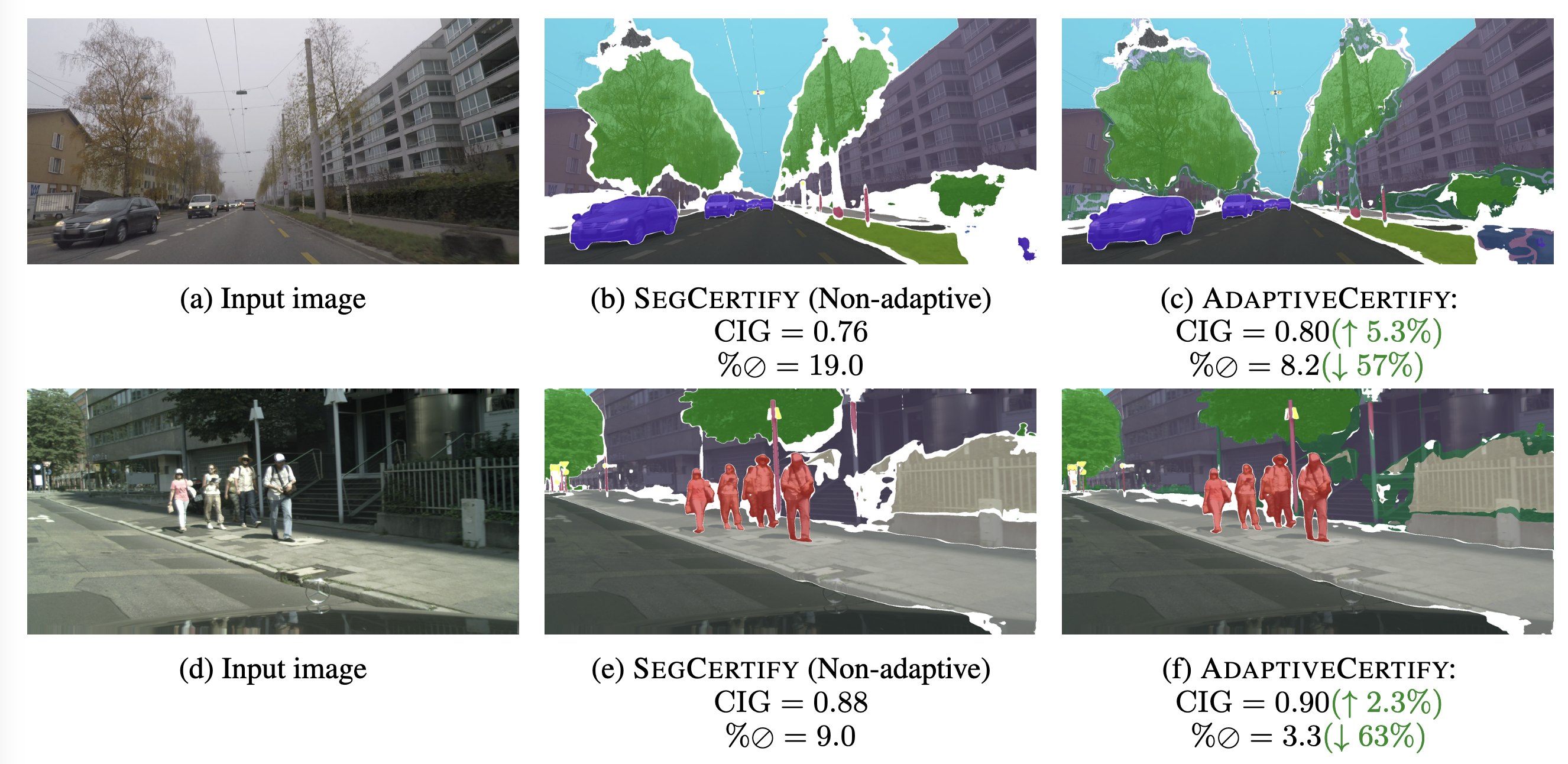
Visualization of results from adaptive hierarchical certification. The baseline method, SEGCERTIFY (middle), has a large number of gray ‘abstained’ pixels. In contrast, ADAPTIVECERTIFY (right) successfully certifies many of these pixels to coarser levels (e.g., certifying some road pixels as ‘flat ground’), thus providing more meaningful certified information. Image source: (Chiang et al., 2023)
Similarly, E et al., 2023 proposed Localized Randomized Smoothing for multi-output tasks like image segmentation and node classification. The core idea is that to accurately segment a part of an image, one only needs to protect the information in that part and its immediate vicinity, while stronger “noise” can be applied to distant, less relevant areas. This approach dramatically improves the model’s defense against global perturbations while maintaining high accuracy in critical regions.
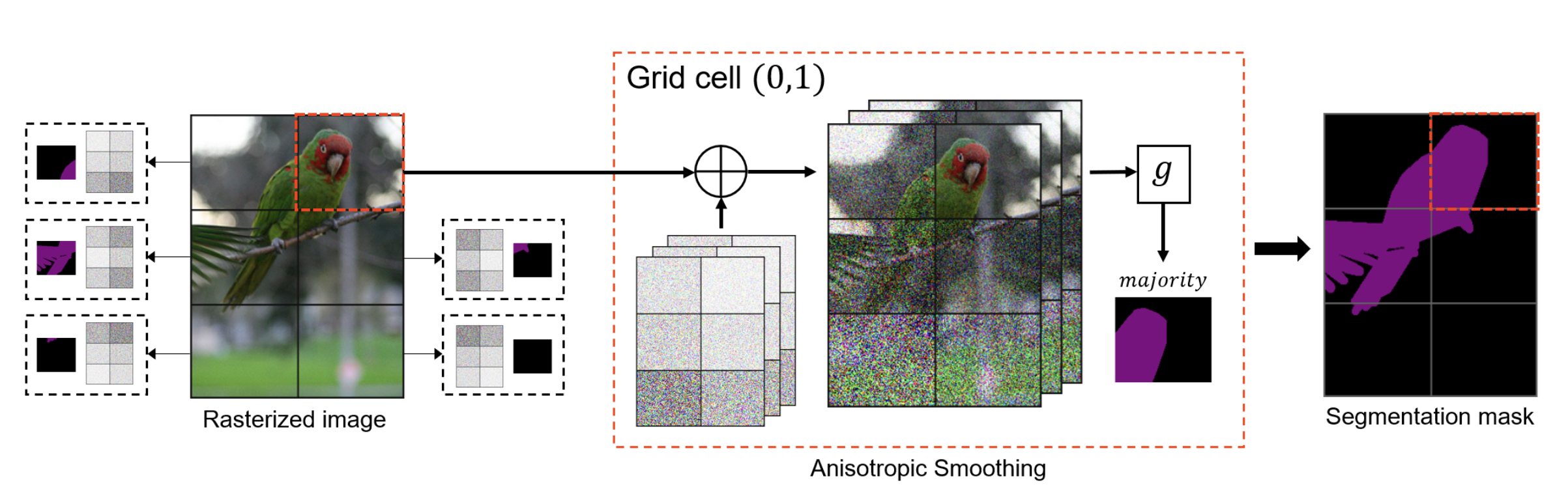
The workflow of Localized Randomized Smoothing. To certify the segmentation result of the top-right grid (containing the parrot’s head), the system generates a series of noisy images where the noise applied to the top-right is significantly weaker than in other areas. By repeating this process for each grid cell and stitching the results, a final segmentation map that is both highly accurate and robust is obtained. Image source: (E et al., 2023)
Although randomized smoothing is powerful and scalable, the robustness guarantee it provides is probabilistic, meaning there is always a tiny failure probability (e.g., $\alpha=0.001$). For safety-critical applications like autonomous driving, this probabilistic guarantee may still be insufficient. Therefore, another research frontier is dedicated to developing defense methods that can provide deterministic guarantees, ensuring that the model’s prediction will absolutely not change within a specified perturbation range.
The main challenge for such methods is that the perturbation sets for many real-world disturbances (like geometric transformations) are highly non-convex, making verification extremely difficult.
Yang et al., 2023 were the first to successfully integrate deterministic geometric robustness certification into the training process, proposing the Certified Geometric Training (CGT) framework. The core technical contribution is a Fast Geometric Verifier (FGV), which is thousands or even tens of thousands of times faster than existing tools. This leap in speed makes it feasible to perform geometric robustness verification in every iteration of training. By optimizing for robustness over randomly sampled small local intervals during training, CGT enables the model to generalize to global robustness across the entire target transformation range.

The verifiable safety boundary of CGT in an autonomous driving scenario. CGT not only enables the autonomous driving model to accurately predict the steering angle (blue prediction line closely follows the green ground truth line) but, more importantly, provides a strict verifiable safety boundary (red area). This boundary guarantees that even if the input image undergoes any rotation within ±2°, the model’s steering prediction will never go outside this region, providing a deterministic safety promise for the system. Image source: (Yang et al., 2023)
Similarly, in the 3D point cloud domain, Jia et al., 2023 proposed the first framework that can provide a deterministic $L_0$-norm robustness guarantee for point cloud classifiers. The core idea is to partition the input point cloud into multiple disjoint sub-clouds using a hash function, and then perform a majority vote on the independent predictions for each sub-cloud.

Optimizing sub-cloud classification in PointCert using a Point Cloud Completion Network (PCN). To address the difficulty of classifying sparse sub-clouds with standard classifiers, a practical variant of PointCert adds a Point Cloud Completion Network (PCN) before the classifier. It first ‘completes’ the sparse sub-cloud into a full shape before classification, thereby improving the accuracy of the voting process. Image source: (Jia et al., 2023)
Since perturbing one point affects at most a few sub-cloud predictions, the final prediction remains unchanged as long as the “winning margin” in the vote is large enough. Based on this, PointCert derives a tight formula for the certifiable perturbation size, which precisely quantifies the maximum number of points that can be added, deleted, or modified while guaranteeing the prediction remains constant.
An emerging and highly promising direction is to shift the focus of defense from traditional discriminative models to generative models. Research by Wang et al., 2023 demonstrates that diffusion models are not only powerful generators but can also be used as certifiably robust classifiers.
The classification principle is as follows: given an input image (which may be perturbed), we attempt to denoise it using the diffusion model, conditioned on every possible class. The class that allows the image to be reconstructed with the lowest reconstruction error is considered the model’s prediction.
The robustness of this method is rooted in the diffusion model’s deep learning of the data manifold. An adversarial perturbation slightly pushes a data point off its original, true manifold. When denoising is conditioned on the wrong class, the model tries to pull this point towards a completely different manifold, resulting in a high reconstruction error. The study theoretically proves that the diffusion classifier has a small Lipschitz constant, providing a mathematical basis for its inherent smoothness and robustness.
Efficient Defenses
Although defense techniques like Adversarial Training (AT) are effective, their immense computational cost has been a major barrier to their widespread adoption. Therefore, a crucial research direction is to significantly improve the efficiency of defenses while maintaining strong robustness. Adversarial Purification offers a promising path by decoupling the defense task from model training, “cleaning” the input at inference time. However, purification methods based on diffusion models, while effective, are too slow for real-world, real-time applications due to their iterative denoising process.
The work by Lei et al., 2024 on OSCP was specifically designed to resolve this core conflict. The study proposes a framework that can complete purification in a single step, achieving a remarkable balance between speed and effectiveness.
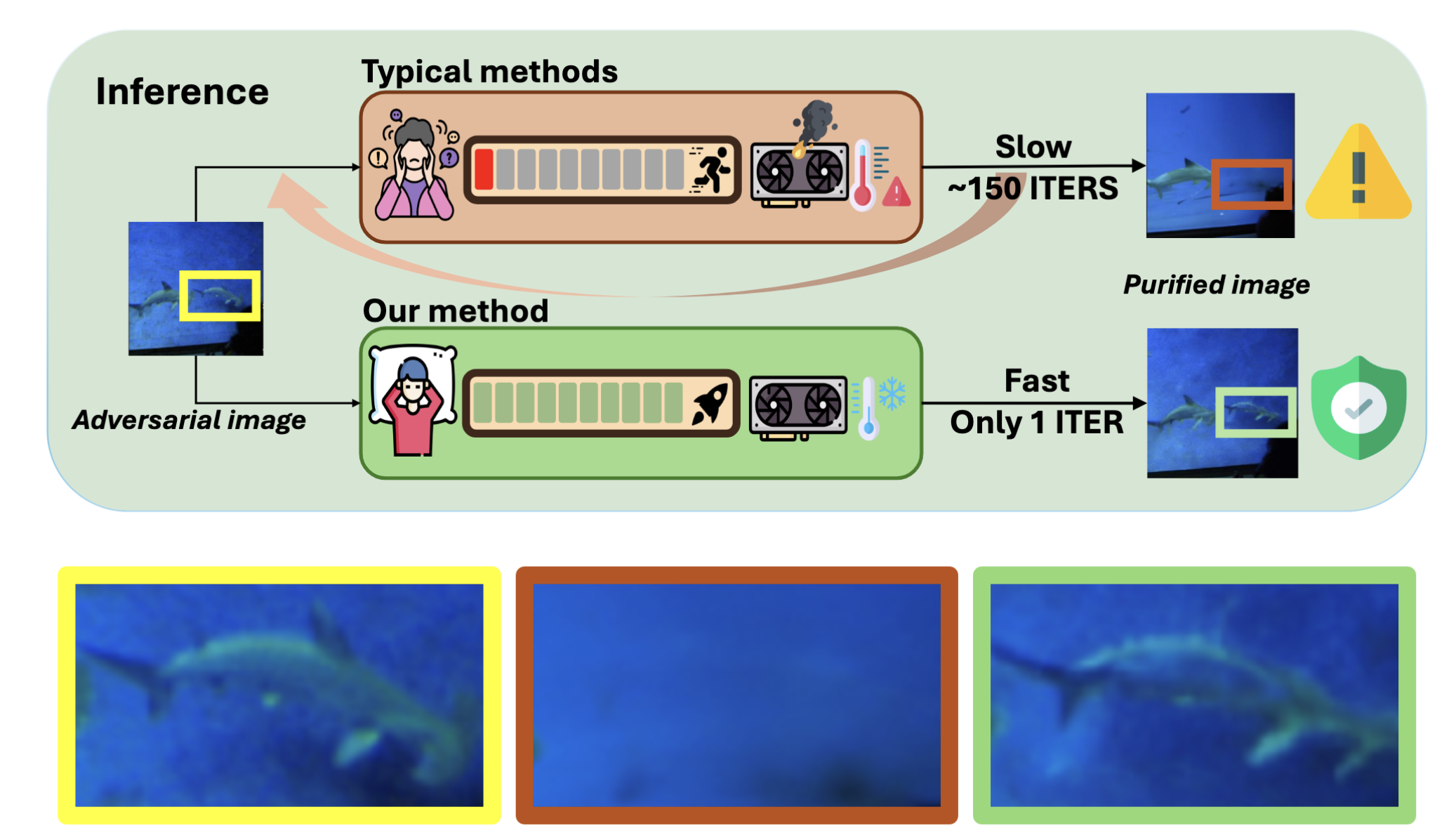
The speed and effectiveness advantages of the OSCP framework. The introductory figure of the paper uses a vivid analogy to illustrate its core contribution. Traditional purification methods (top) are time-consuming and inefficient, and their results are often suboptimal. In contrast, the OSCP framework (bottom) is extremely efficient and can effectively remove adversarial noise while better preserving the original details and quality of the image. Image source: (Lei et al., 2024)
The implementation of the OSCP framework relies on two core innovations: GAND, a training method designed for “one-step purification,” and CAP, an inference process that ensures the purified image does not lose its semantic integrity.
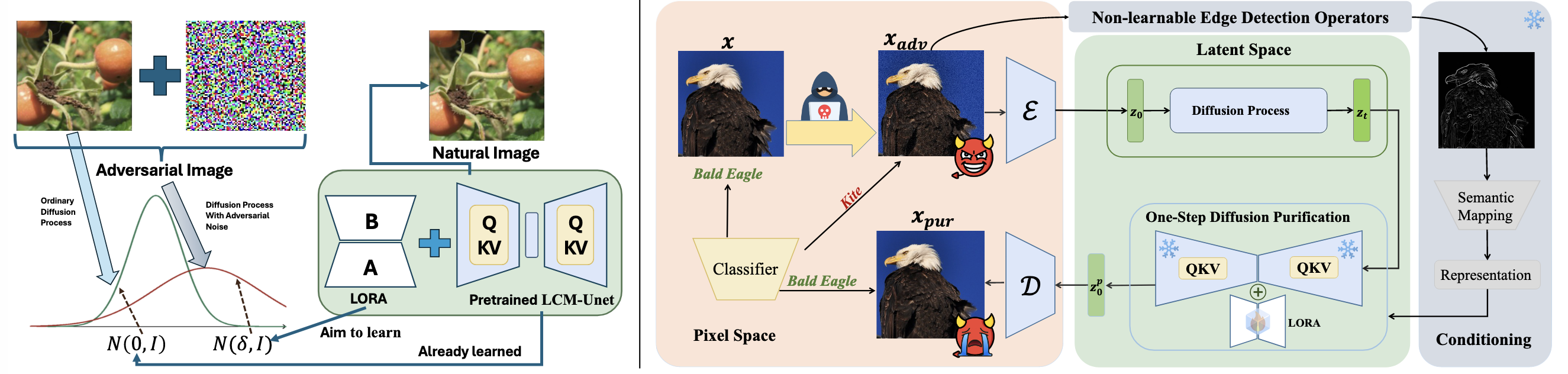
The technical flowchart of the OSCP framework (GAND training and CAP inference). The GAND training stage (a) teaches the model to handle adversarial noise, while the CAP inference stage (b) uses an edge map as guidance to enforce structural integrity during denoising. Image source: (Lei et al., 2024)
The introduction of the CAP process fundamentally solves a fatal flaw of traditional purification methods: the loss of semantic information. Many purification methods are “blind” in their noise removal, potentially erasing complex details that are part of the original image along with the noise.
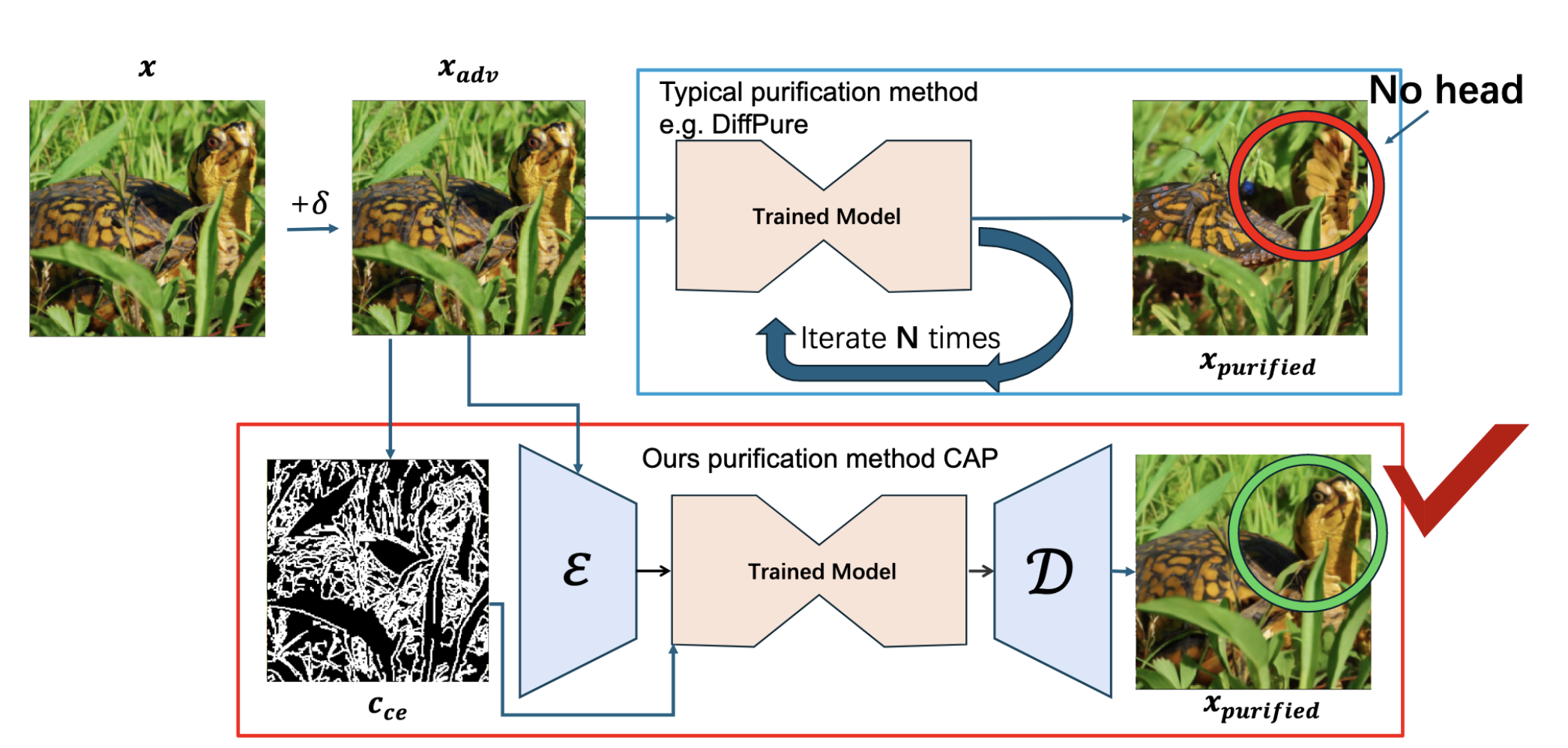
A comparison between the CAP method and traditional purification methods. A typical purification method (blue box), when processing an attacked image of a turtle, might remove the adversarial perturbation but also erase the turtle’s head. In contrast, the CAP method (red box), guided by the edge map, performs a directed purification, perfectly preserving the turtle’s head while removing the noise. Image source: (Lei et al., 2024)
This ability to preserve semantic information ultimately translates into the ultra-high quality of the purified images.

A quality comparison of purified images. Whether dealing with natural textures or artificial details, the traditional method DiffPure (column c) leads to significant blurring and loss of detail. In contrast, the images purified by OSCP (column d) are clear and sharp, far surpassing traditional methods in visual quality and being nearly indistinguishable from the original clean images (column a). Image source: (Lei et al., 2024)
Robustness in Modern Models
The robustness of deep learning models is not a one-size-fits-all problem; it is closely tied to the model’s internal architecture. Different architectures, such as Vision Transformers (ViT), Spiking Neural Networks (SNNs), or prototype-based networks, exhibit unique vulnerabilities and defense potentials due to their distinct inductive biases and information processing mechanisms.
The rise of Vision Transformers (ViT) has revolutionized computer vision, but their robustness has also become a central issue. Lacking the strong inductive biases of CNNs like “convolution” and “locality,” ViTs heavily rely on large-scale data and strong data augmentation in standard training. Researchers have found that directly transferring this successful paradigm to adversarial training does not yield optimal results.
The work by Bai et al., 2023 proposed a groundbreaking “light recipe” for this challenge. The study discovered that for adversarial training, strong data augmentations (like MixUp, CutMix) are not only unhelpful but are in fact harmful. The root cause is the conflict between the two strong regularization methods—adversarial training and strong data augmentation—which makes the training task exceptionally difficult and interferes with the generation of effective adversarial examples. Therefore, the core of this recipe is to remove all strong data augmentations, supplemented by “ε-warmup” (gradually increasing the adversarial perturbation strength in the early stages of training) and a larger “weight decay.”
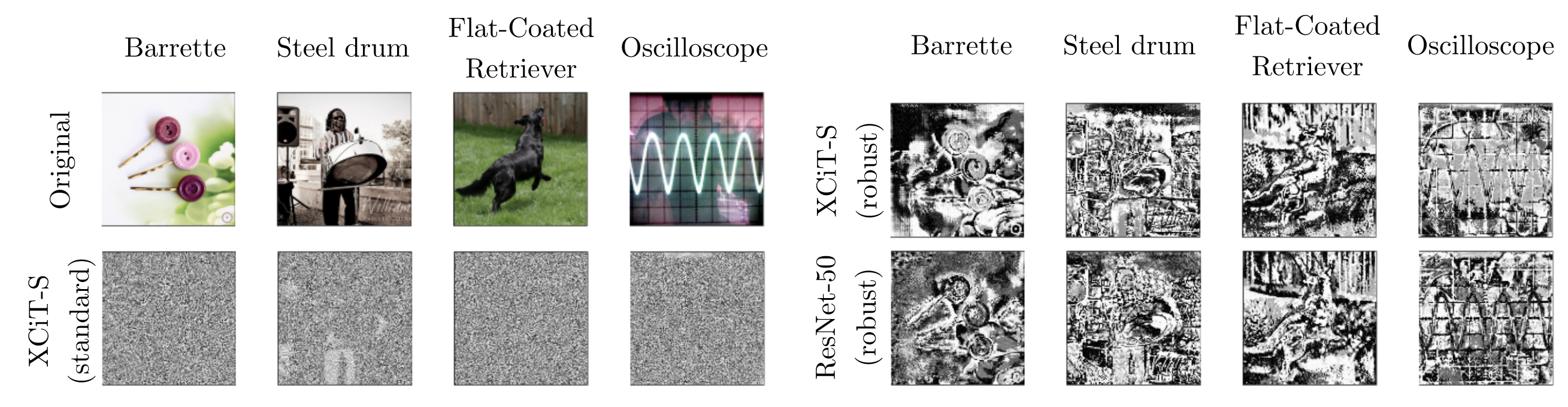
The state-of-the-art robustness of the light recipe on ImageNet. A ViT model trained with this ’light recipe’ achieved state-of-the-art performance in adversarial robustness on ImageNet, significantly outperforming the best-performing CNN models at the time. Image source: (Bai et al., 2023)
With the popularization of large pre-trained models, parameter-efficient fine-tuning techniques like Prompt Tuning have become a new hotspot. However, ensuring robustness within the prompt tuning paradigm presents new challenges. Research from Fu et al., 2023 found that naively applying adversarial training to prompt tuning leads to severe gradient obfuscation, creating a false sense of security. This is because most model parameters are frozen during prompt tuning, causing the input gradients to become “shattered” and rendering traditional gradient-based attacks ineffective.
To solve this problem, the study proposed the ADAPT framework. Its core is to design an adaptive adversarial attack that considers both the learnable “prompt” parameters $\boldsymbol{\theta}_p$ and the input image $\boldsymbol{x}$ when generating attacks, rather than just the input. The corresponding adaptive adversarial prompt training then uses this stronger attack to optimize the prompt parameters. Experiments show that the ADAPT framework achieves adversarial robustness comparable to fully fine-tuning the entire model while only tuning about 1% of the parameters.
Self-supervised learning has also proven to be an effective way to enhance the robustness of ViTs. The work by Gao et al., 2023, inspired by the Information Bottleneck theory, proposed a novel self-supervised adversarial pre-training method. The core idea is to have the model reconstruct a completely clean, complete original image from an input that has been doubly corrupted (adversarial perturbation + random masking).
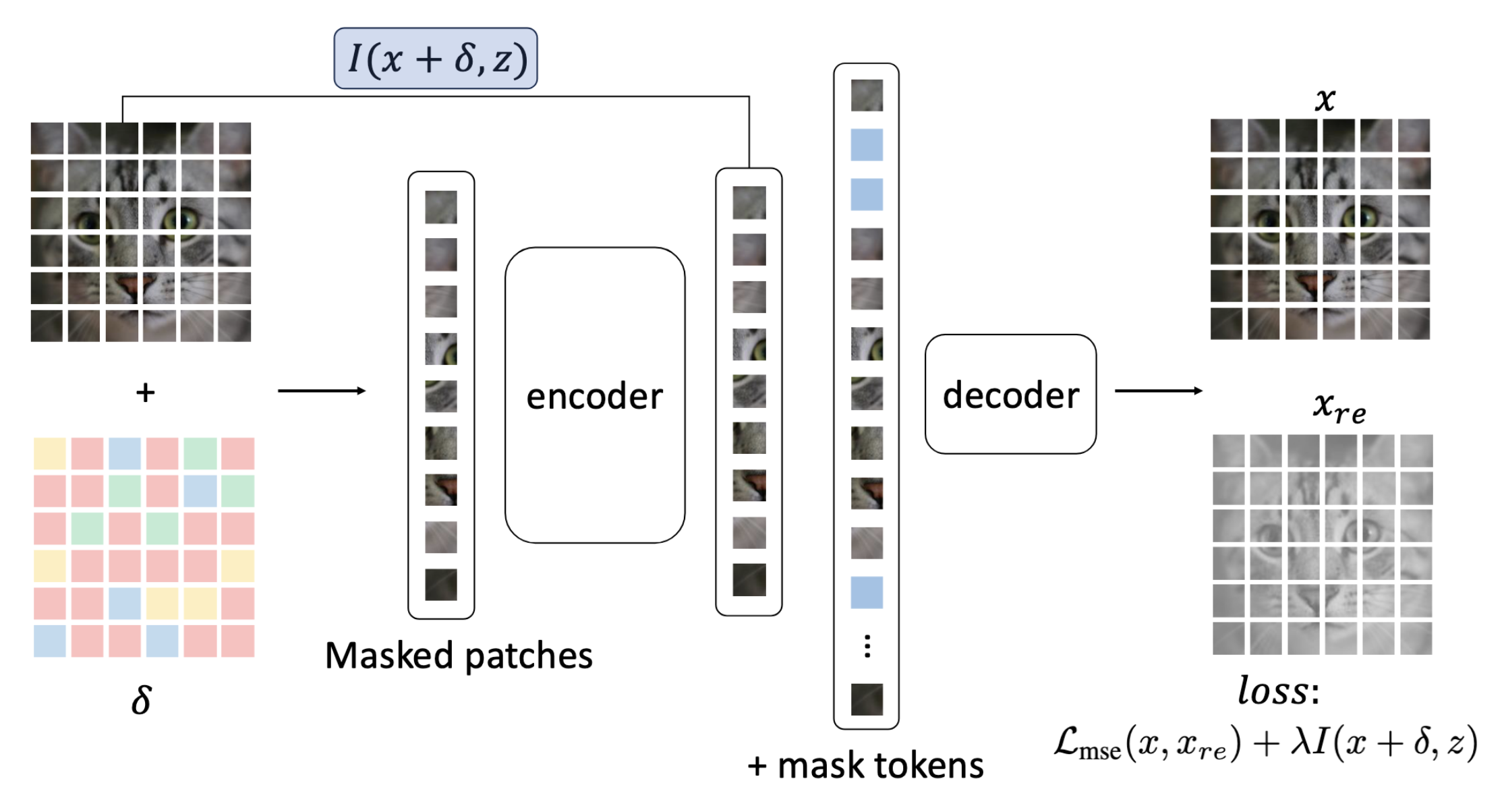
The pre-training process of MIMIR. The training objective of MIMIR consists of two parts. The first is to minimize the reconstruction loss between the reconstructed image and the original clean image. The second is to minimize the mutual information between the corrupted input and the latent features extracted by the encoder. This compels the encoder to discard information related to the perturbation. Image source: (Gao et al., 2023)
An encoder trained in this manner naturally extracts features that are highly “immune” to adversarial perturbations and learns a smoother loss landscape.
Spiking Neural Networks (SNNs), known for their event-driven nature and spatio-temporal information processing, have garnered attention for their energy efficiency and biological plausibility. The work by Zhang et al., 2023 elevates the study of SNN robustness to a new level. The research innovatively treats an SNN as a Temporal Self-Ensemble model, viewing the network states over $T$ timesteps as an ensemble of $T$ independent sub-networks.
Based on this perspective, the paper identifies two key challenges to SNN robustness: the vulnerability of individual temporal sub-networks and the propagation of vulnerability across timesteps. To address this, the study proposes the Robust Temporal self-Ensemble (RTE) training framework. RTE aims to simultaneously enhance the robustness of each temporal sub-network and suppress the propagation of adversarial perturbations across timesteps through a unified loss function. Experiments demonstrate that RTE achieves a better robustness-accuracy trade-off than existing SNN adversarial defense methods on multiple benchmarks.
Prototype-Based Networks are considered an important direction in explainable AI due to their case-based reasoning. However, research by Saralajew et al., 2025 points out that many existing deep prototype networks may produce misleading explanations that are inconsistent with the model’s actual decision-making process due to their unconstrained weights.

Unfaithful explanations caused by unconstrained weights. As shown, the PIPNet model incorrectly classifies the input ‘Fish Crow’ as a ‘Common Raven.’ Although the similarity score of the input image to the ‘Fish Crow’ prototype is higher, the model assigns a disproportionately large weight to the ‘Common Raven’ prototype, allowing weaker evidence to dominate the final decision. Image source: (Saralajew et al., 2025)
To address this issue, the study extends the “Classification-by-Components” (CBC) model. The new CBC architecture can be seen as a deep Radial Basis Function (RBF) network with well-defined interpretability constraints. It constrains the weights through probabilistic modeling and introduces negative reasoning, considering not only “what it is” but also “what it is not.”

A CBC model learning concepts through positive and negative reasoning. To identify a ‘Vermilion Flycatcher,’ the CBC model not only learns an abstract concept of a ‘slender beak’ through positive reasoning but also confirms the absence of a ‘stout, conical beak’ through negative reasoning, thereby distinguishing it from the similarly colored ‘Northern Cardinal.’ Image source: (Saralajew et al., 2025)
This reasoning approach, based on concept comparison, makes the model’s decision-making process more comprehensive and robust, achieving a unification of performance, interpretability, and robustness.
Robustness in Cost-sensitive Cases
The challenge of adversarial robustness is not confined to generic image classification tasks. When deep learning models are deployed in high-stakes, specific domains such as autonomous driving and medical imaging, robustness issues take on new, more complex forms. The input data (e.g., 3D point clouds, multi-modal sensor streams) and task objectives (e.g., 3D object detection, surface reconstruction) in these fields place unprecedented demands on model reliability.
In autonomous driving systems, precise 3D perception of the surrounding environment is the cornerstone of safe navigation. However, both LiDAR-based and camera-based 3D perception models face severe threats from adversarial attacks.
The work by Zhang et al., 2023 provides the first systematic robustness evaluation of mainstream LiDAR-based 3D object detectors. The study found that imperceptible perturbations to point clouds can cause a sharp decline in the performance of top detection models. The research systematically analyzes three attack modalities: Point Perturbation, Point Detachment, and Point Attachment. A key finding is that a model’s vulnerability is closely related to its feature representation method: Voxel-based models, which discretize space and to some extent disrupt the continuity of attack gradients, are generally more robust than Point-based models that process raw points directly.
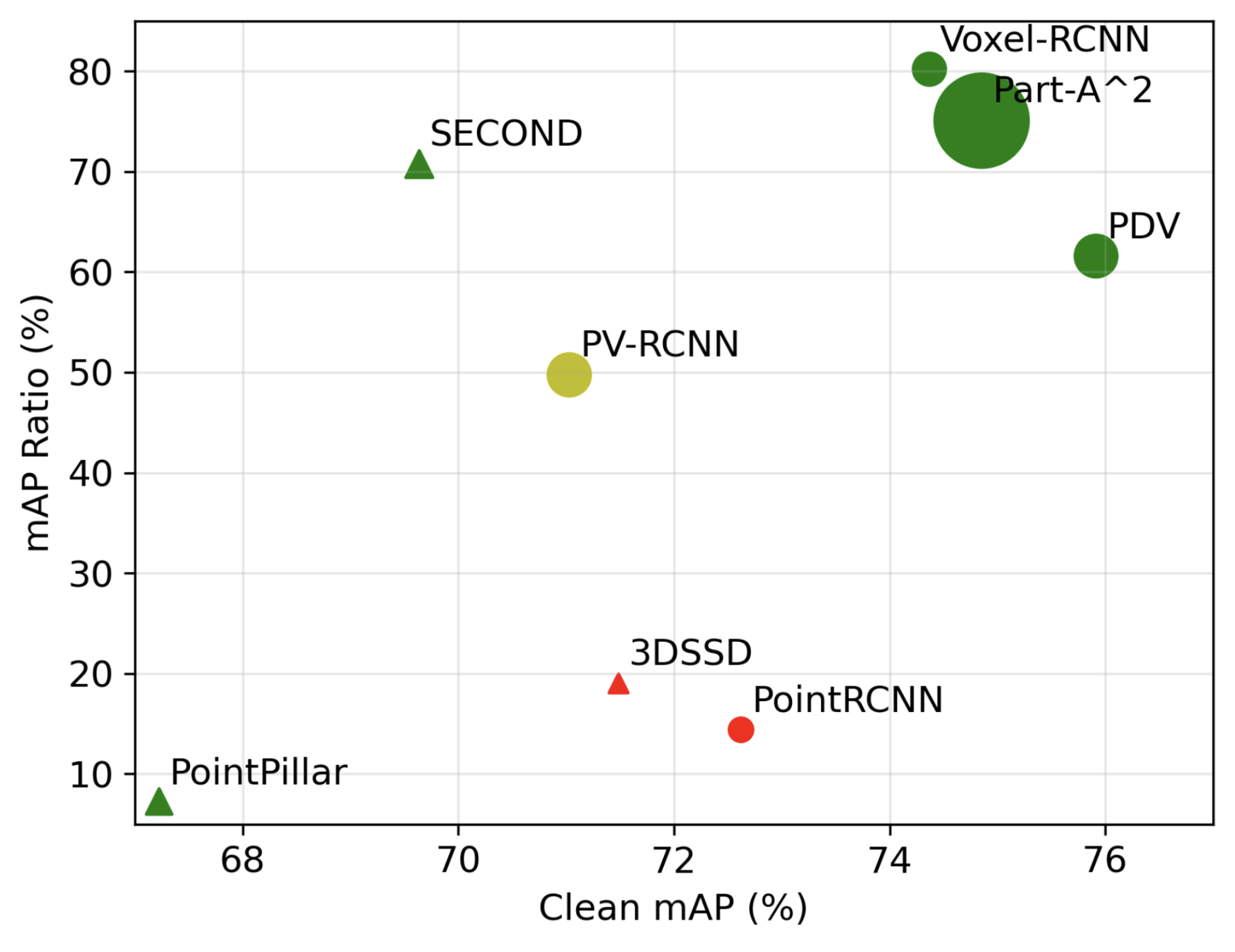
The accuracy-robustness trade-off for different 3D detector architectures. Voxel-based models (red) generally cluster in the top-right corner, exhibiting higher accuracy and robustness. In contrast, point-based models (green) are generally less robust. PointPillar (the green triangle at the bottom left) is an extreme outlier, being exceptionally sensitive to point perturbations due to its unique feature encoding method. Image source: (Zhang et al., 2023)
To enhance the performance of camera-only 3D object detection, Chen et al., 2023 proposed a pioneering knowledge distillation framework. The core idea is to use a powerful, LiDAR-based “teacher” model and a 2D instance segmentation “teacher” model to jointly guide the training of a “student” model that uses only multi-camera images. This approach aims to boost the student’s performance without increasing its inference-time computational complexity.
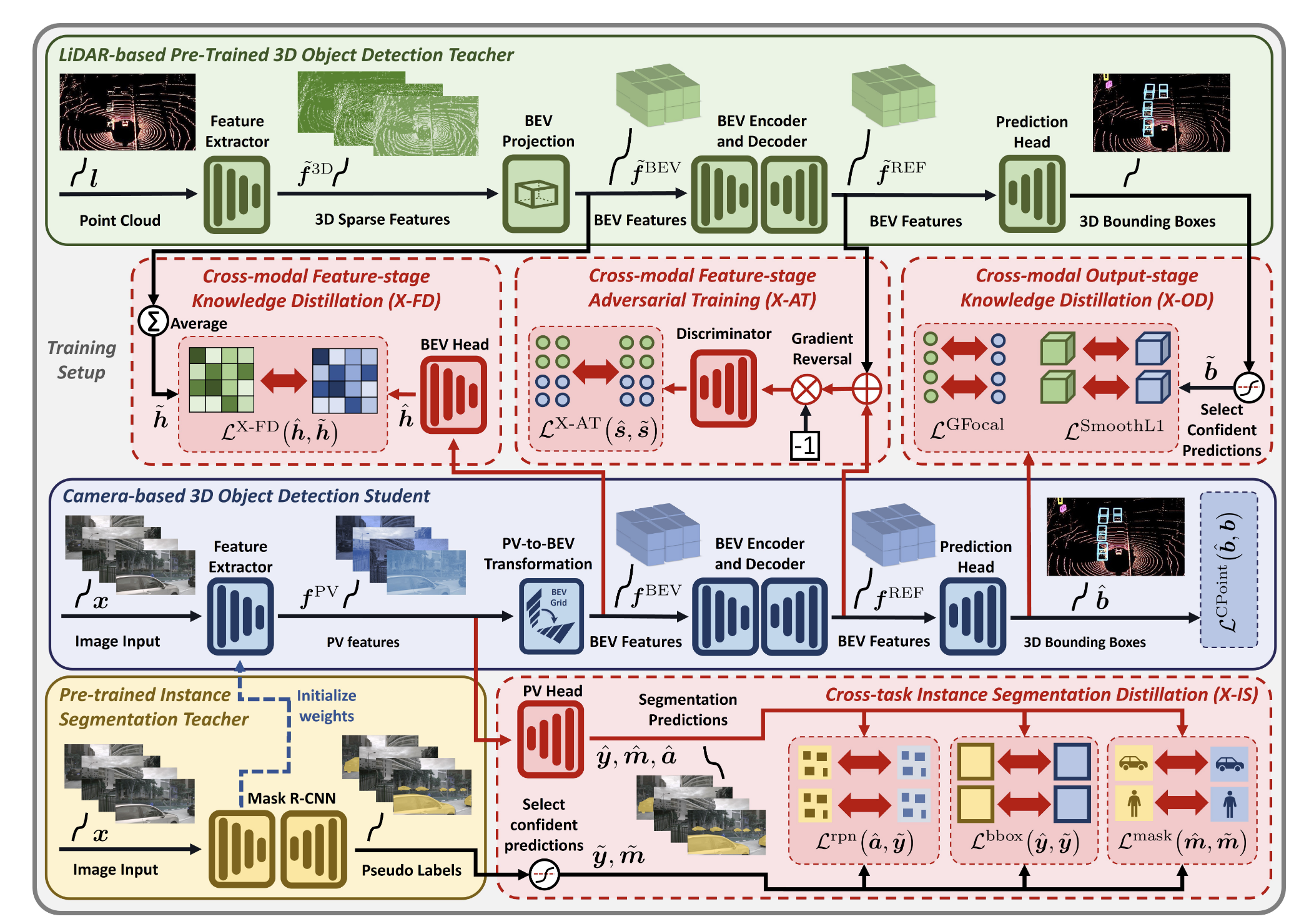
The cross-modality, cross-task, and cross-stage knowledge distillation framework of X³KD. X³KD is a highly synergistic training system. The LiDAR teacher provides Cross-modal Feature Distillation, Adversarial Training, and Output Distillation to the student in the Bird’s-Eye View space. Meanwhile, the 2D segmentation teacher provides Cross-task Instance Segmentation Distillation in the Perspective View space. Through this comprehensive guidance, the student’s 3D perception capabilities are significantly improved. Image source: (Chen et al., 2023)
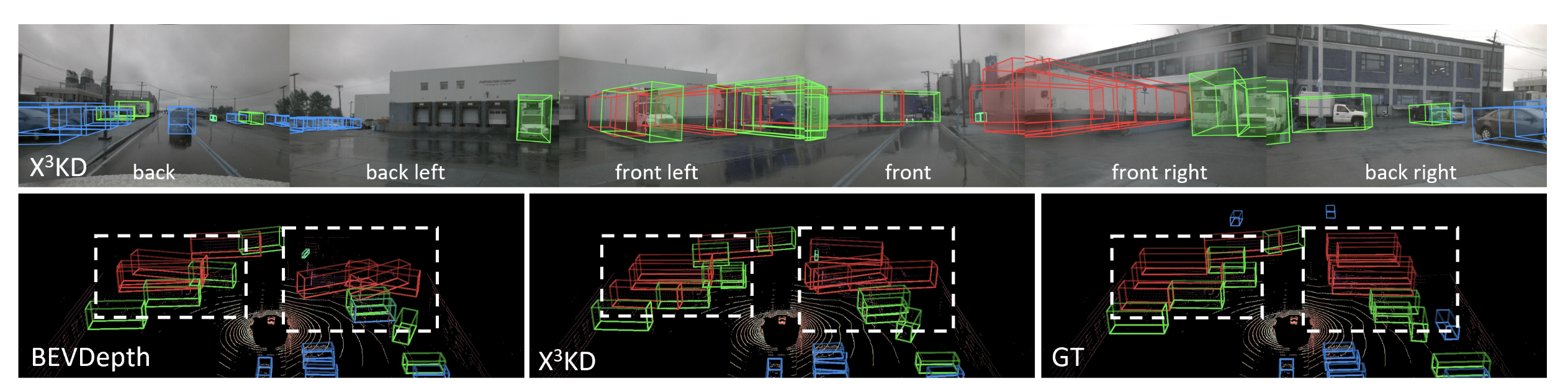
A qualitative comparison between X³KD and a baseline model. The bird’s-eye view comparison shows that the baseline model, BEVDepth (left), produces chaotic and incorrectly oriented detections in complex scenes. In contrast, the model trained with X³KD (middle) yields very clean and accurate detections that are highly consistent with the ground truth (GT, right). Image source: (Chen et al., 2023)
Besides detection, another critical 3D perception task is surface reconstruction. The work by Tang et al., 2023 introduces a novel, efficient, and precise method for reconstructing object surfaces from unorganized, noisy point clouds. The core innovations of SurfR are parallel multi-scale feature extraction and a cross-scale attention mechanism.
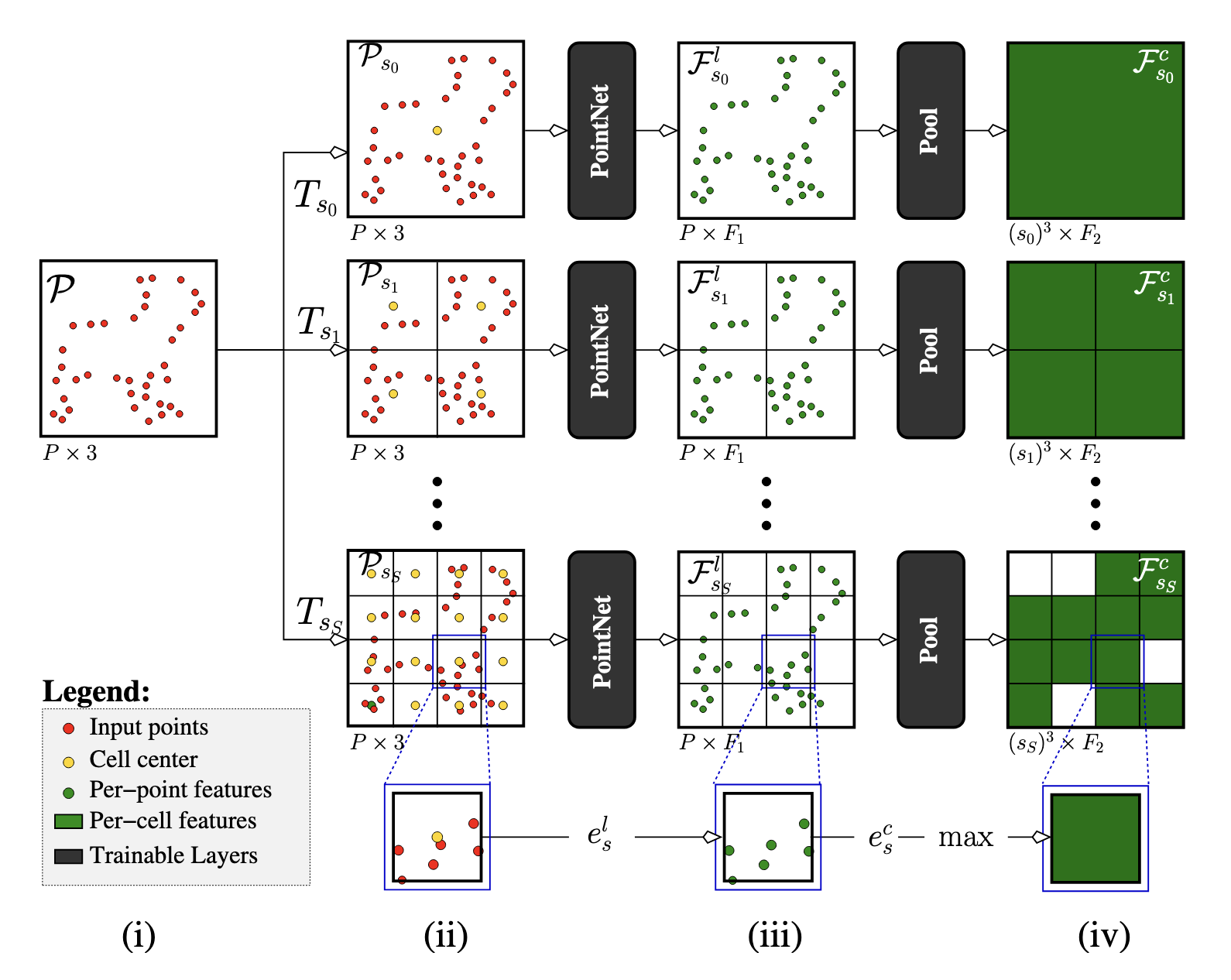
The multi-scale feature extraction and cross-scale attention mechanism of SurfR. SurfR first partitions the point cloud into grid cells and extracts features in parallel at multiple scales. Then, for a given query point, it samples neighboring features at each scale. Finally, a Transformer encoder processes the features from different scales, using self-attention to effectively fuse information across scales. Image source: (Tang et al., 2023)
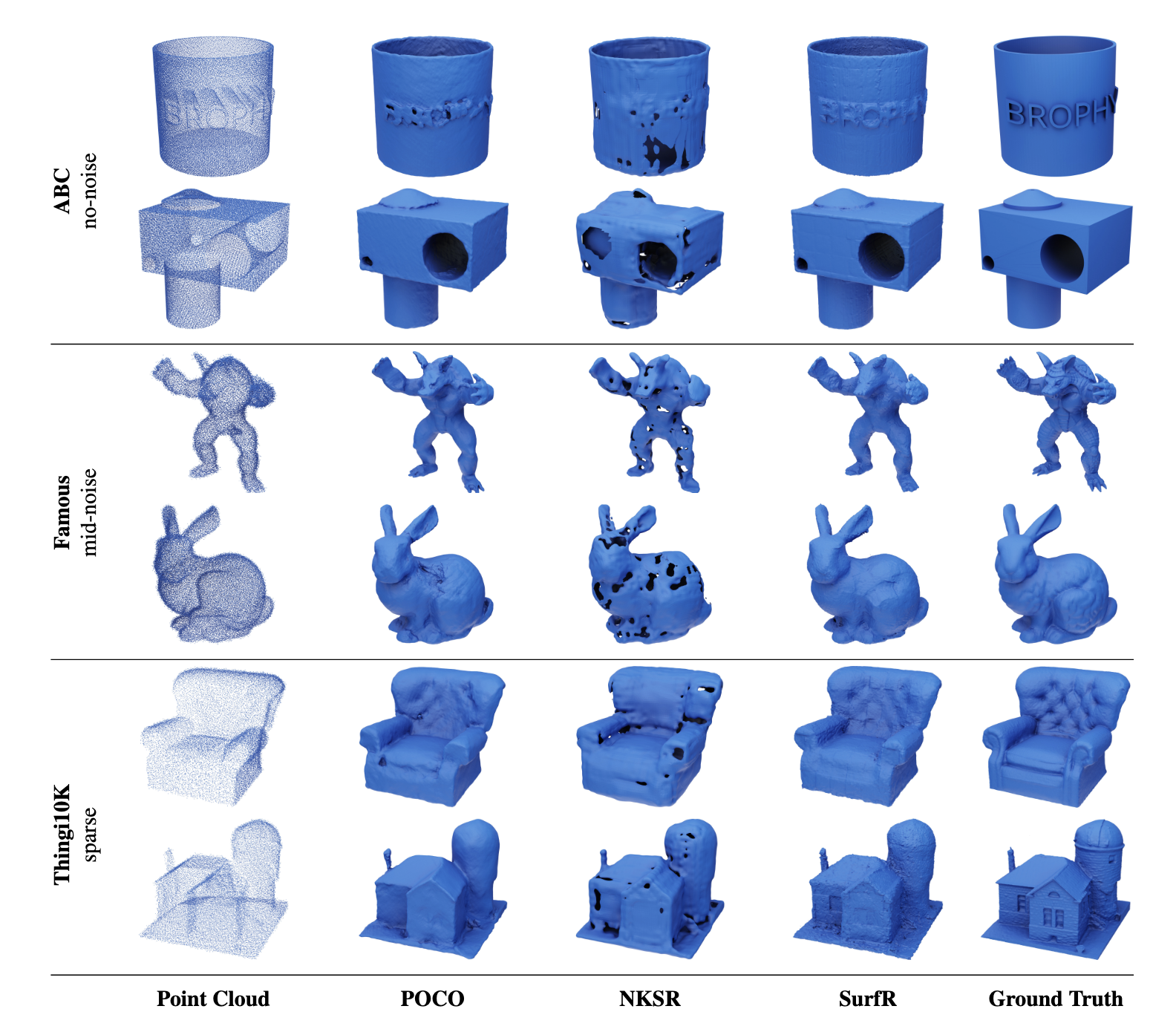
The reconstruction performance of SurfR under different noise levels. SurfR can generate high-quality surfaces and preserve rich geometric details when processing point clouds with varying levels of noise and sparsity. Its performance is superior or comparable to existing methods on multiple benchmarks, while achieving an order-of-magnitude speedup. Image source: (Tang et al., 2023)
Finally, we must recognize that in systems like autonomous driving, threats come not only from attacks on individual sensors but also from multi-modal semantic attacks on the entire system. Mao et al., 2023 proposed the first robustness certification framework for multi-sensor fusion systems. This framework can ensure that an autonomous vehicle’s perception module remains stable and reliable when facing common real-world semantic attacks like rotation and translation, providing mathematical safety guarantees.
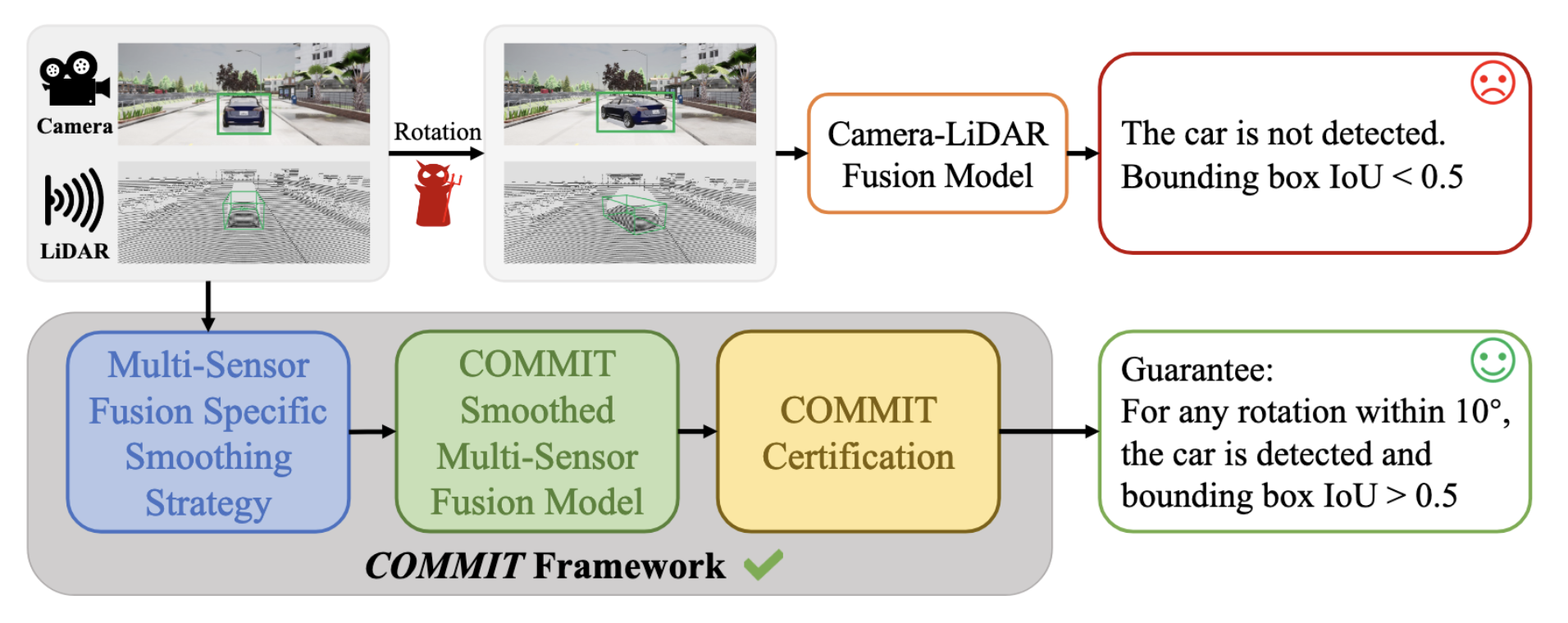
The core idea of the COMMIT framework. A standard camera-LiDAR fusion model (top) may fail to detect a vehicle completely when subjected to a minor rotation attack. The COMMIT framework (bottom), through a randomized smoothing strategy tailored for multi-sensor fusion, can provide a provable robustness guarantee, for instance, ensuring that the Intersection over Union (IoU) of vehicle detection remains above 0.5 for any rotation within 10 degrees. Image source: (Mao et al., 2023)
The importance of robustness is particularly pronounced in fields like medical imaging analysis, where a model’s incorrect judgment could directly endanger a patient’s life. Such applications face not only the threat of adversarial attacks but also the more common challenge of Domain Shift, where a model trained on data from one institution (e.g., Hospital A) may experience a significant performance drop when deployed at another institution (Hospital B) with a slightly different data distribution.
The work by Weng et al., 2023 provides the first large-scale experimental analysis of the performance of adversarial robustness in domain generalization scenarios.
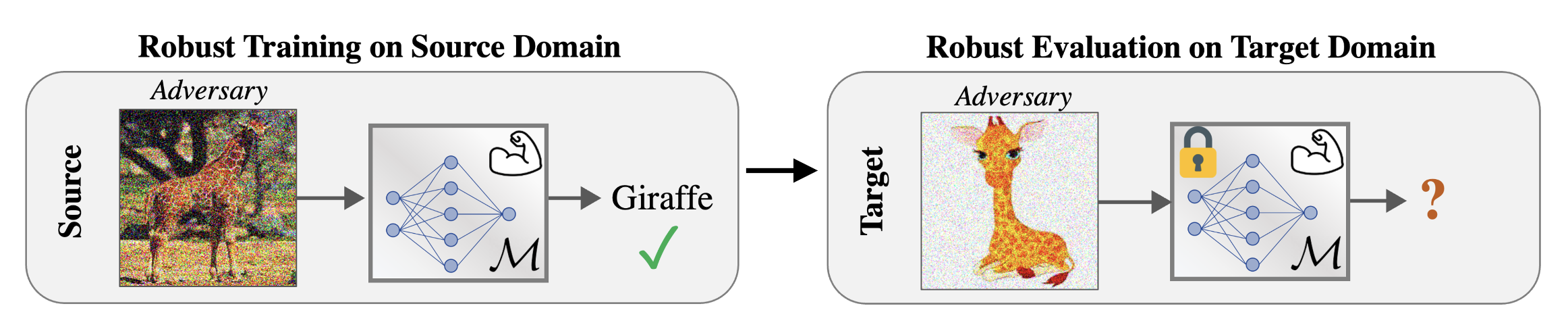
The core problem of robustness generalization under domain shift. The central question of this research is whether robustness acquired through adversarial training in a ‘source domain’ (e.g., real photos) can ‘generalize’ to an unseen, stylistically different ’target domain’ (e.g., cartoons). Image source: (Weng et al., 2023)
The study finds that both empirical and certified robustness can generalize to a considerable extent to new, unseen data distributions. A surprising discovery is that the visual similarity between the source and target domains does not correlate well with the level of robustness generalization. The study also extends its experiments to a real-world medical imaging application.
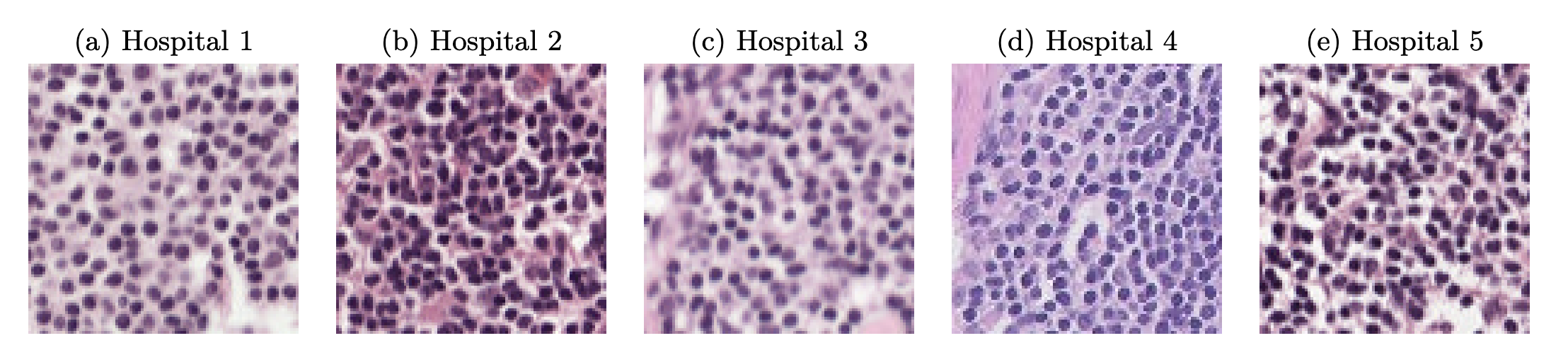
Domain shift in the CAMELYON17 dataset. Histopathology image slides from five different hospitals exhibit clear distribution shifts due to differences in scanning equipment and staining procedures. The experiments demonstrate that in this real-world medical scenario, adversarial augmentation not only significantly improves the generalization of robustness but also has a minimal impact on the model’s accuracy on clean data. Image source: (Weng et al., 2023)
Besides domain shift, high-risk domains also face the challenge of asymmetric error costs. For example, in medical diagnosis, misclassifying a malignant tumor as benign (a false negative) is far more costly than misclassifying a benign tumor as malignant (a false positive).
Horváth et al., 2023 address this issue by proposing the first provably cost-sensitive adversarial defense. This method no longer treats all misclassifications as equally costly but allows the user to define a cost matrix $\boldsymbol{C}$ to encode the severity of different types of misclassifications.
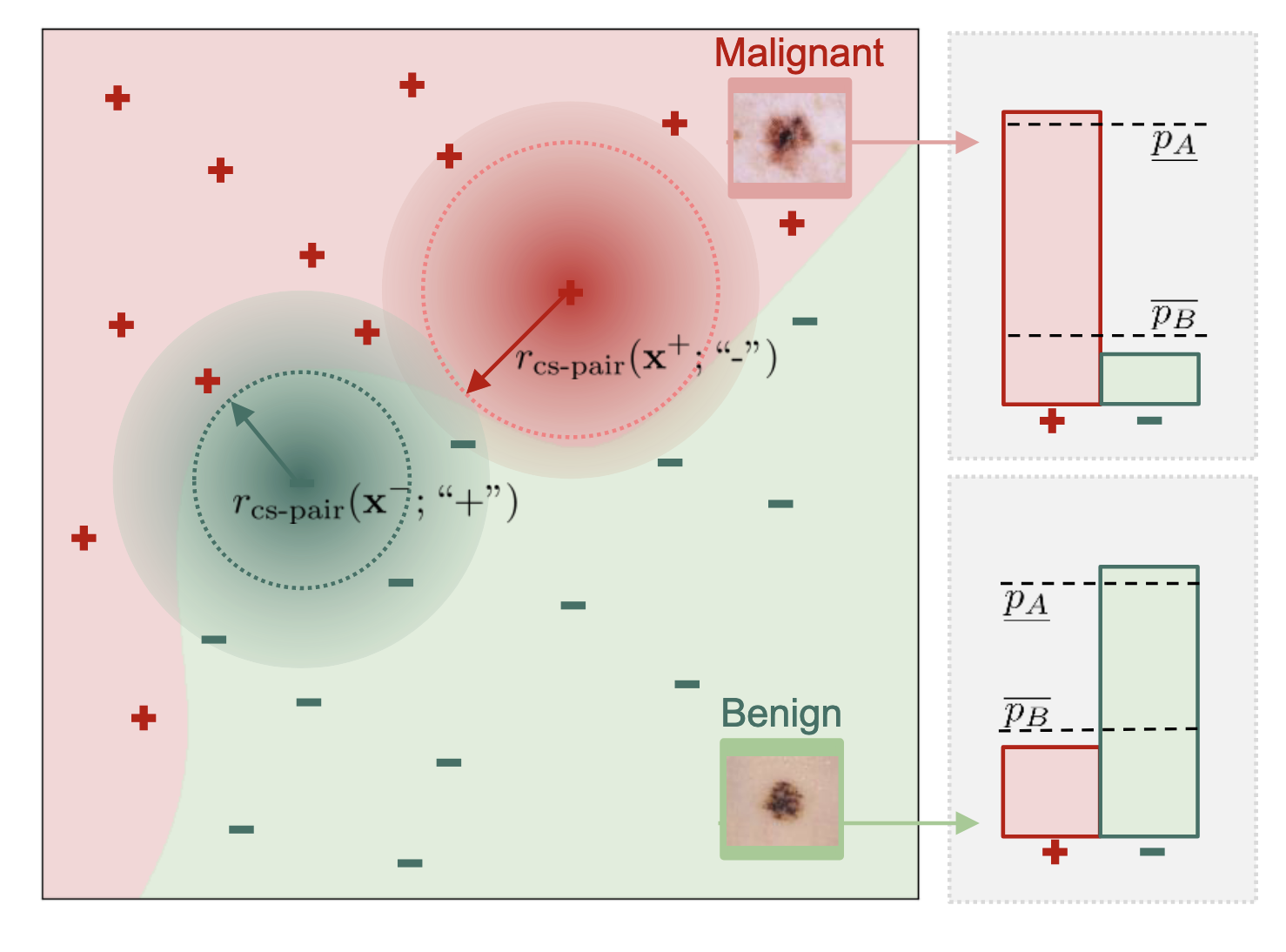
Visualization of the cost-sensitive certified radius. The core of this method is to define a cost-sensitive certified radius. For a malignant tumor sample (red plus), the certified radius guarantees that any perturbation within this ‘safe zone’ will not cause it to be misclassified as the high-cost ‘benign’ class (green minus). The size of this radius depends on the gap between the model’s confidence in the correct classification and its confidence in the target incorrect class. Image source: (Horváth et al., 2023)
By designing a training method (Margin-CS) that specifically optimizes this confidence gap, the research enables models in safety-critical applications to prioritize defending against the most dangerous, highest-cost attacks.
Tang et al., 2024 model the image restoration problem (e.g., denoising, deraining, super-resolution) as an Optimal Transport (OT) problem and innovatively introduce the “transport residual” as a unique clue specific to a particular degradation to guide the restoration process.
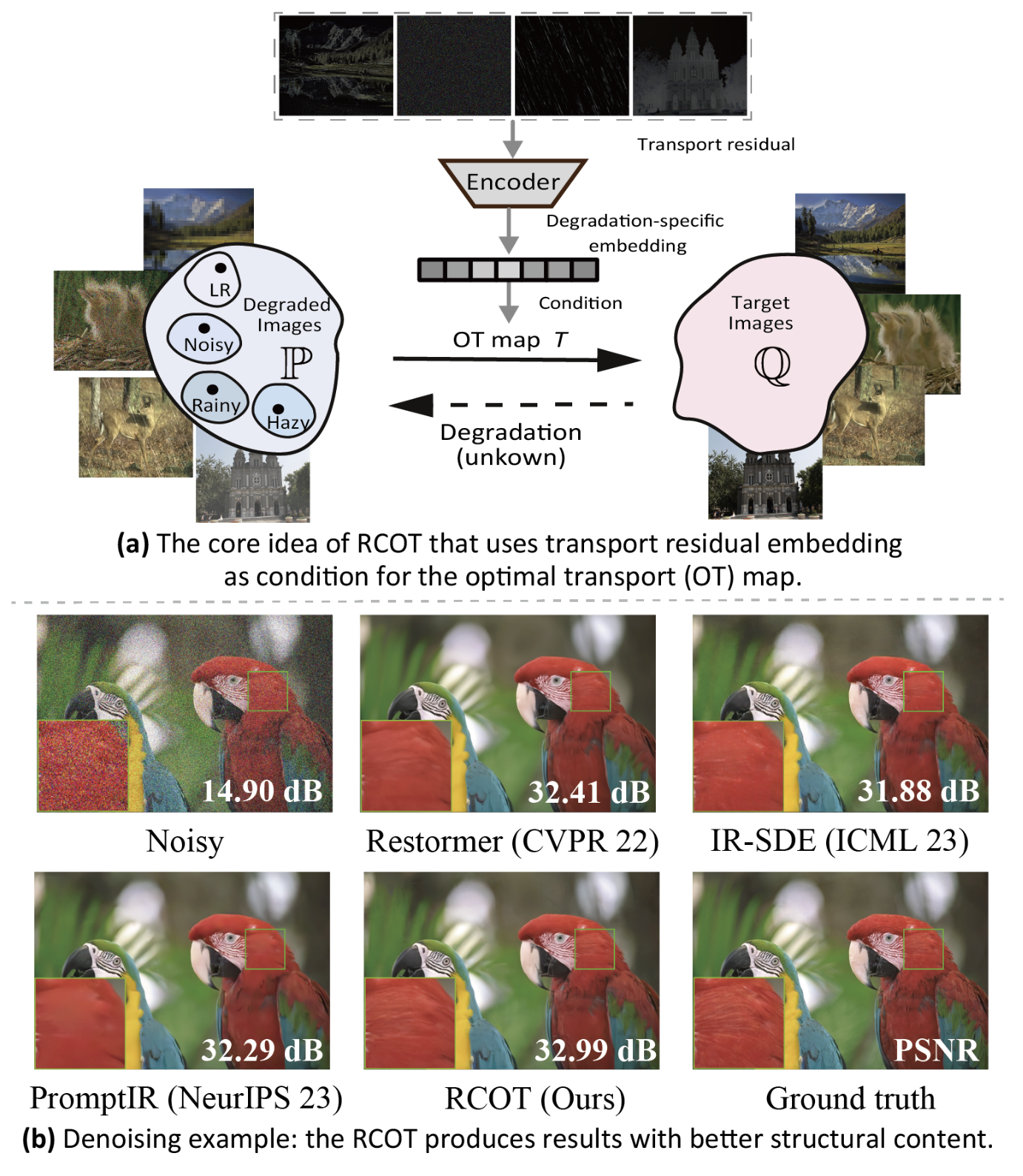
The core idea of the RCOT framework. As shown in (a), the RCOT method first analyzes the ‘residuals’ corresponding to different degradation types and encodes them into a ‘diagnostic report.’ This embedding is then used as a condition to guide the optimal transport map, achieving a precise, ‘symptomatic’ restoration. The denoising results in (b) demonstrate that RCOT can more effectively preserve and reconstruct fine image structures. Image source: (Tang et al., 2024)
With the rise of generative models, especially diffusion models, their own robustness and how to improve their performance have become new research hotspots. Ben-Iwhi et al., 2024 proposed a new technique called Group Orthogonalization Regularization (GOR), which aims to address the widespread parameter redundancy in deep neural networks by reducing the correlation between convolutional filters.

The improvement in generation quality of diffusion models by GOR. Combining GOR with LoRA for text-to-image diffusion model fine-tuning, the GOR-optimized model (bottom row) generates images with richer, more vivid details (especially in the eyes) than the standard method (top row), significantly improving generation quality. Image source: (Ben-Iwhi et al., 2024)
Experiments also demonstrate that adding GOR during adversarial training can effectively improve model robustness. This indicates that optimizing the internal parameter structure of a model can not only enhance its core performance but also strengthen its resilience against adversarial attacks.